반응형
가설검정
가설검정이란?
- 표본 데이터를 이용해 모집단에 대한 가설이 타당하지 판단하는 통계적 절차
- p값(p-value)이라는 수치를 계산하여 가설을 지지하는지 여부를 판단
확증적 자료분석(가설검증형 데이터 분석)(CDA: Confirmatory Data Analysis)
- 미리 세운 가설을 검정(확률적으로 판단)하는 접근법
탐색적 자료분석(EDA: Exploratory Data Analysis)
- 전체 데이터를 탐색적으로 해석하는 접근법 (처음에 가설 없음)
군(그룹)
- 실험군(Treatment Group) : 어떠한 조치를 취한 집단
- 대조군(Control Group) : 실험군과 비교⋅대조를 위해 마련한 집단
귀무가설과 대립가설
자, 우선 변화/효과/차이가 없다고 가정하고 시작하자.
그런데 관측된 데이터가 그 가정과 너무 안 맞으면, 그 가정을 버리자.
→ 이렇게 ‘기본 가정(디폴트)’으로 세우는 게 귀무가설(Null Hypothesis, H0)이고,
그 귀무 가설이 깨졌을 때 선택되는 대안이 대립가설(Alternative Hypothesis, H1)
귀무가설(Null Hypothesis, H0)
- 귀무가설은 우리가 계산할 확률의 기준
- 밝히고자 하는 가설의 부정 명제
- p-value는 “H0가 참이라고 가정했을 때 이런 데이터가 나올 확률”을 계산
- “귀무가설 기각 못함 = 귀무가설 참”이 아님 → 표본이 작거나 노이즈가 크면, 거짓인 H0도 기각 못할 수 있음
귀무가설을 ‘기각’한다는 말의 의미
- 통계는 ‘증명’보다는 ‘기각’의 언어를 씀
- 귀무가설 기각 : “차이가 없다”는 가정 아래서는 지금 데이터가 너무 이상하다 → 따라서 차이가 있다고 볼 근거가 충분하다.
- 귀무가설 기각 못함 : 데이터가 그럭저럭 “차이 없음” 세계에서도 나올 만하다 → 차이가 있다고 말할 근거가 부족하다.
- “기각 못함”은 “참이다”가 아니님 단지 “반박할 만큼 강한 증거가 없다”는 뜻임
대립가설(Alternative Hypothesis, H1 또는 Ha )
- 내가 주장하고 싶은 방향
- 밝히고 싶은 가설
- 대립가설은 “세상은 이런 방향일 수도 있다”를 포괄함
- ‘증명’되는 게 아니라 ‘지지’되는 것임
- 통계는 확률적 판단이라 “절대적 확정”이 아니라 “이 정도면 우연이라 보기 어렵다”를 말함
p값(p-value)
- 현실에서 얻은 데이터가 귀무가설이 옳은 가상 세계에서는 얼마나 나타나기 쉬운가, 또는 어려운가를 평가하는 값
- 귀무가설이 옳다고 가정했을 때, 지금 관측한 결과와 같거나 더 극단적인 결과가 나올 확률
p값과 유의수준 alpha를 이용한 가설 판정
- p-value가 유의수준 alpha보다 작은 경우, 귀무가설 아래에서 관측된 결과가 우연으로 발생했다고 보기 어렵기 때문에 귀무가설을 기각하고, 해당 차이는 통계적으로 유의미하다고 판단하여 대립가설을 채택한다.
- 반대로 p-value가 유의수준 alpha보다 큰 경우, 귀무가설을 기각할 충분한 근거가 없으며, 통계적으로 유의미한 차이를 발견하지 못하여 귀무가설을 기각 없이 판단을 보류한다. 이는 귀무가설이 참이라는 의미는 아니다.
- 유의수준 alpha
- 귀무가설을 기각할 것인지 채택할 것인지의 판단 경계로 이용하는 값
- 과학계에서는 보통 alpha=0.05
양측검정 vs 단측검정
- 양측검정 : 양음수 양쪽을 모두 고려하는 가설검정 방법으로 ‘변화가 있는지만’ 알고 싶거나 방향을 미리 정하지 않았을 때 사용(대부분의 과학 연구 기본값)
- 단측검정 : 어느 한쪽만을 고려해 넓이를 계산하는 방법으로 방향이 명확하고 사전에 정해졌을 때, 반대 방향은 의미 없거나 불가능할 때 사용
t검정
- t검정(t-test)은 표본 평균을 이용해서 모집단 평균(또는 두 평균의 차이)이 우연인지 아닌지를 판단하는 방법
- 관측된 평균 차이가 데이터의 흔들림을 고려했을 때 충분히 크다고 볼 수 있는가?
- t값 : 표본 평균이 귀무가설 평균에서 표준오차 몇 배만큼 떨어져 있는가를 계산한 값, 확률 아니고 거리임, 관측된 평균 차이를 데이터의 흔들림으로 나눈 표준화된 거리
- t값 공식 : (두 그룹 간의 평균 차이) / (그 차이의 표준 오차)

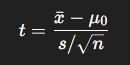
t검정의 종류
- 일표본 t검정 (One-sample t-test) : “이 집단 평균이 특정 값과 다른가?”
- 한 집단의 평균이 어떤 기준값 μ0 과 다른지 알고 싶을 때
- H0 : μ = μ0 (모집단의 평균은 00이다.)
- H1 : μ ≠ μ0 (또는 >, <) (모집단의 평균은 00이 아니다. 또는 크거나 작다.)
- 이표본 t검정 (Two-sample t-test, 독립표본) : “서로 다른 두 집단 평균이 같은가?”
- 서로 독립인 두 집단의 평균을 비교할 때
- H0 : μ1 = μ2 (2개 집단의 평균값은 같다 = 평균값의 차이가 0이다)
- H1 : μ1 ≠ μ2 (2개 집단의 평균값이 다르다 = 평균값의 차이가 0이 아니다)
(실제로는 μ1−μ2 = 0 형태로 씀)
(1) 등분산 t검정 (pooled t-test) : 두 집단 분산이 같다고 가정
- sp : 합동분산(pooled variance)
- 자유도 : n1+n2−2
- 현실에서는 잘 안 씀
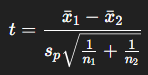
(2) 웰치(Welch) t검정 : 등분산 가정 없음
- 자유도 : Welch–Satterthwaite 근사식
- 분산 달라도 안전, 표본수 달라도 안정적
- 실무 및 연구에서 많이 사용
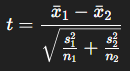
- 대응표본 t검정 (Paired t-test) : “같은 대상의 전/후 평균 차이가 0인가?”
- 같은 대상에서 두 번 측정했을 때(전/후 비교)
- 또는 1 : 1로 짝지어진 데이터일 때
- 두 집단을 비교하는 것이 아니라 차이값 하나의 평균을 검정

- H0 : μd = 0
- H1 : μd ≠ 0
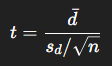
- dˉ : 차이의 평균
- sd : 차이의 표준편차
- 자유도 : n−1
z분포 vs t분포
| 구분 | z분포 | t분포 |
|---|---|---|
| 분산 정보 | 모분산 앎 | 모분산 모름 |
| 꼬리 | 얇음 | 두꺼움 |
| 표본 크기 | 큼 | 작음 |
| 자유도 | 없음 | 있음 |
제1종 오류와 제2종 오류
제1종 오류
- 사실은 귀무가설이 맞는데, 틀렸다고 판단한 경우
- 실제로 아무런 차이가 없음에도 차이가 있다고 판단해 버리는 잘못
- 제1종 오류 확률 = α (유의수준 보통 0.05)
제2종 오류
- 사실은 귀무가설이 틀렸는데, 맞다고 판단한 경우
- 정말로 차이가 있는데도 차이가 있다고 말할 수 없어, 귀무가설을 기각하지 않는 판단을 내려버리는 것
- 제2종 오류가 일어나는 확률 = β
- 제 2종 오류가 일어나지 않는 확률, 즉 정말로 차이가 있을 때 차이가 있다고 올바르게 판단할 확률 → 검정력(Power of Test) = 1 − β
검정력(Power of Test) = 1 − β
- 진짜 효과가 있을 때(귀무가설이 거짓) 그걸 제대로 잡아내서 귀무가설(H₀)을 기각할 확률
- 보통 검정력 $1-\beta$가 0.8(80%) 이상이 되도록 표본크기를 설계하는 것이 이상적
- 검정력을 높이려면 표본크기(n)↑, 효과크기↑, α↑, 변동성↓
양적 변수의 성질
정규성(normality)
- 데이터가 정규분포를 따른다고 볼 수 있는 성질
모수검정(Parametric)
- 데이터가 어떤 분포(주로 정규)에서 나왔다고 가정하고, 그 분포의 모수(평균, 분산)에 대해 검정하는 방식
- 조건이 맞으면 검정력이 높음
- 추정/해석이 작관적(평균 차이 등)
- 정규성/등분산성/독립성 같은 가정이 깨지면 결과가 왜곡될 수 있음
비모수검정(Nonparametric)
- 특정 분포(정규 등)를 강하게 가정하지 않고 검정하는 방식
- 많은 경우 ‘값 자체’보다 ‘순위’를 사용
- 정규성이 깨져도 비교적 안전
- 이상치에 덜 민감한 경우가 많음
- ‘평균 차이’가 아니라 ‘분포의 위치 차이(중앙값/순위)’ 해석이 되는 경우가 많음
- 윌콕슨 순위합 검정(Wilcoxon Rank Sum Test) : 평균값 대신 각 데이터 값의 순위에 기반하여 검정을 실시, 주로 중앙값의 차이를 비교
- 맨 - 휘트니 U 검정, 플리그너 - 폴리셀로 검정(Fligner-Policello Test), 브루너 - 문첼 검정(Brunner-Munzel Test)
등분산성(homoscedasticity)
- 여러 집단(또는 조건)에서 분산이 동일하다고 볼 수 있는 성질
분산분석
- 3개 집단 이상의 평균값 비교
다중비교 검정
- 집단이 n개인 경우 집단의 수가 늘어날수록 제1종 오류가 일어나기 쉬워집니다.
- 몇 번씩 검정을 반복하는 것을 통해, 실은 차이가 없는데도 차이가 있다고 말하는 잘못이 간단히 일어나 버리게 됩니다.
3집단 이상의 비모수검정
- 크러스컬-윌리스 검정(Kruskal-Wallis Test)
- 스틸-드와스 검정(Steel-Dwass Test)
- 스틸 검정(Steel Test)
범주형 데이터
이항검정 (Binomial Test)
- 성공/실패처럼 두 가지 결과만 있는 경우
- 한 비율이 어떤 기준값과 다른지 검정
- 표본이 작아도 사용 가능
- 범주가 2개일 때만 가능
카이제곱(χ²) 검정
- 범주가 2개 이상일 경우
- 관측된 개수들이 기대한 개수와 얼마나 어긋났는지를 측정

(1) 카이제곱 적합도 검정 (Goodness-of-Fit Test)
- 한 개의 범주형 변수
- 관측된 분포가 기대 분포와 맞는지 확인
- H0 : 관측 분포 = 기대 분포
- H1 : 관측 분포 ≠ 기대 분포
(2) 카이제곱 독립성 검정 (Test of Independence)
- 두 개의 범주형 변수
- 두 변수가 서로 관련이 있는지 확인
- H0 : 두 변수는 독립이다
- H1 : 두 변수는 독립이 아니다 (관련 있음)
'IT' 카테고리의 다른 글
| 통계학 기초 - 회귀, 일반화 선형모형(GLM), 로지스틱스 회귀 (0) | 2026.04.16 |
|---|---|
| 통계학 기초 - 상관과 회귀, 상관계수, 비모수상관계수, 회귀 분석 (0) | 2026.04.16 |
| 통계학 기초 - 2 (0) | 2026.04.15 |
| 통계학 기초 - 1 (0) | 2026.04.15 |
| 판다스(Pandas) - 데이터 변환 기능과 데이터 구조 최적화 (0) | 2026.04.12 |