반응형
p-해킹(p-hacking)
- 의도하든, 의도하지 않든 p값을 원하는 방향으로(유의수준 𝛼가 0.05 미만이 되도록) 조작하는 행위
- 데이터를 본 뒤 분석·수집·보고 방식을 여러 번 바꿔가며, 유의수준 𝛼가 0.05 미만이 될 때까지 시도하고 그중 성공한 결과만 보고하는 행위(또는 관행)
- 유의한 결과를 얻기 위한 분석·설계·보고상의 모든 조작적 관행을 포괄하는 넓은 개념
HARKing(Hypothesis After the Results are Known)
- 데이터를 얻어 결과를 보고 나서 가설을 만드는 행위
- 결과를 먼저 본 다음에, 그 결과에 맞게 ‘처음부터 이 가설을 세운 것처럼’ 서술하는 행위
- p-해킹(p-hacking)과 HARKing은 같이 일어나는 경우가 많음
| 구분 | p-해킹 | HARKing |
|---|---|---|
| 핵심 문제 | 유의한 결과를 만들어냄 | 결과의 출처를 숨김 |
| 언제 발생 | 분석 과정 | 보고/해석 과정 |
| 특징 | 여러 분석 시도 | 가설의 시간 왜곡 |
| 공통점 | 1종 오류 증가 | 재현성 저하 |
인과관계와 상관관계
- 변수 사이의 관계 → 상관 관계, 인과 관계
인과관계(Causation)
- A가 B의 원인이다라는 관계
- 원인과 결과의 관계 (방향성 존재)
- 인과관계를 알면 원인 변수를 변화시킴으로써(개입), 결과 변수를 바꿀 수 있다.
상관관계(Correlation)
- 두 변수가 함께 움직이는 경향이 있다
- 관련성(Association)
- A가 커질수록 B도 커지는 경향 → 양(+)의 상관
- A가 커질수록 B는 작아지는 경향 → 음(-)의 상관
- 상관관계는 2개 변수 X, Y 사이의 관련성이므로, 한쪽 변수로부터 또 다른 변수를 예측할 수 있다.
허위상관(Spurious Correlation)
- 인과관계는 없지만 상관관계는 있을 때
- 인과관계가 있는 것처럼 보이는 상관
다중공선성(multicollinearity)이란?
- 독립변수들(X) 사이에 선형관계(한 변수가 다른 변수들의 조합으로 표현됨)가 생기는 상태 → 회귀가 어떤 계수를 얼마나 줘야 하는지 결정을 못하고 계수 추정이 불안정해지고 해석이 흔들릴 수 있음
- 독립변수들(X) 중 하나가 다른 독립변수들의 조합으로 완벽하게 설명될 수 있는 상태를 말함 이 경우, 모델은 각 변수의 순수한 영향력을 개별적으로 계산할 수 없게 되어 오류가 발생함
pd.get_dummies()더미 변수를 활용할 때drop_first=True옵션을 사용하여 기준이 될 더미 변수 하나를 처음부터 제거해서 위 문제를 해결함 해당 옵션을 사용하면 제일 첫번째 변수가 기준이 됨
- 완전 다중공선성 (Perfect)
- 어떤 변수가 다른 변수들의 조합으로 정확히 표현됨
- 회귀가 원리적으로 불가능하거나 에러/자동제거 발생
- 더미를 전부 넣었을 때가 대표적
- drop_first=True가 해결
- 약한/높은 다중공선성 (Imperfect)
- 완벽하진 않지만, 변수들이 서로 강하게 연관됨
- 회귀는 되지만
- 표준오차 커짐
- p-value 커짐
- 계수 불안정해짐
- drop_first=True를 해도 이런 “약한 다중공선성”은 생길 수 있음
다중공선성이 있으면 아래 증상들이 생김
- R²는 높은데 개별 변수 p-value가 이상하게 큼
- 계수 부호가 직관과 다르게 뒤집히기도 함
- 표준오차가 커짐(신뢰구간 넓어짐)
- 데이터 조금만 바뀌어도 계수가 크게 흔들림
상수항(절편) 추가
X_const = sm.add_constant(X)
- 우리가 직접 X 데이터에 1로 꽉 찬 열을 추가함 → 회귀식의 y절편(b)을 계산하기 위해
- 상수항이 없으면 모든 X가 0이면 y도 0이어야 한다는 강제 조건이 걸리기 때문에 현실 데이터에선 이게 말이 안 되는 경우가 많아서 계수들이 왜곡될 수 있음
빈도주의 통계(Frequentist Statstics) vs 베이즈 통계 (Bayesian Statistics)
빈도주의
- 모집단에서 추출할 때의 불확실성
- 고정된 파라미터 θ를 가진 확률분포(모집단)을 상정
- 빈도주의에서의 확률은 무한히 반복 실행한 결과로서의 객관적인 빈도
베이즈
- 확률을 ‘얼마나 확신하는지’
- 모집단분포를 모형화할 때, 분석자가 그 파라미터 $\theta$를 어느 정도 알고 있는지를 확률분포로 나타냄
베이즈 정리
- 새로운 정보를 얻었을 때, 내 생각(확률)을 어떻게 업데이트할지 알려주는 공식
- 원래 이렇게 생각했는데, 이 증거를 보고 나니 생각을 이렇게 바꿔야겠네?
- 베이즈 정리 공식(기본형)
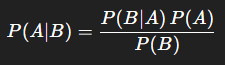
- 사전 확률 (Prior) - P(A)
- 처음에 내가 얼마나 그렇게 믿고 있었는지
- 증거 보기 전 원래 A라고 생각했던 확률
- 가능도 (Likelihood) - P(B∣A)
- 그 가설이 맞을 때, 지금 이 증거가 나올 가능성
- A라면 이런 증거(B)가 얼마나 잘 나오냐?
- 증거 (Evidence) - P(B)
- 증거가 나올 전체 확률
- B가 나오는 전체 확률 (정규화/보정용)
- A일 때도 B가 나오고, A가 아닐 때도 B가 나올 수 있음
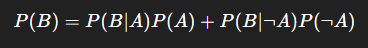
- 사후 확률 (Posterior) - P(A∣B)
- 증거를 보고 나서 새로 업데이트된 확률
- B를 보고 나서 A라고 믿는 정도
'IT' 카테고리의 다른 글
| 데이터 전처리와 시각화 - 파이썬 판다스 (0) | 2026.04.18 |
|---|---|
| 통계학 기초 - AI 머신러닝, 의사 결정 나무 (Decision Tree), 랜덤 포레스트 (Random Forest), K-최근접 이웃 (K-Nearest Neighbor, KNN) (1) | 2026.04.17 |
| 통계학 기초 - 회귀, 일반화 선형모형(GLM), 로지스틱스 회귀 (0) | 2026.04.16 |
| 통계학 기초 - 상관과 회귀, 상관계수, 비모수상관계수, 회귀 분석 (0) | 2026.04.16 |
| 통계학 기초 - 3 (0) | 2026.04.16 |

