1. Online Retail Dataset - 이커머스 취소/반품율 개선 분석
이 데이터셋은 실제 영국 기반의 온라인 소매업체의 거래 기록을 담고 있으며, 2010년 12월 1일부터 2011년 12월 9일까지의 데이터를 포함하고 있습니다. 이 데이터셋은 고객 행동 분석, 구매 패턴 탐색, 전환율 분석 등 다양한 이커머스 분석 실습에 활용됩니다.
📌 학습 목적
결제 완료 단계와 취소/반품 단계를 구분하여 이커머스 전환율을 분석하고, 고객 행동 데이터로부터 전략 수립에 필요한 인사이트를 도출하는 능력을 기릅니다.
- 기간: 2010년 12월 1일 ~ 2011년 12월 9일
- 총 거래 수: 541,909건
- 결측치: 없음(No)
| 컬럼명 | 설명 |
|---|---|
| InvoiceNo | 주문 번호. 각 거래에 고유하게 할당된 6자리 숫자. 'C'로 시작하면 취소된 거래를 의미. |
| StockCode | 상품 코드. 각 상품에 고유하게 할당된 5자리 숫자. |
| Description | 상품 설명. 상품의 이름이나 설명을 나타냄. |
| Quantity | 거래당 구매된 상품의 수량. |
| InvoiceDate | 거래가 발생한 날짜와 시간. |
| UnitPrice | 상품의 단가(파운드 기준). |
| CustomerID | 고객 ID. 각 고객에게 고유하게 할당된 5자리 숫자. |
| Country | 고객이 거주하는 국가의 이름. |
📌 주요 개념
- 유효 주문:
InvoiceNo가 ‘C’로 시작하지 않는 거래 - 취소/반품 주문:
InvoiceNo가 ‘C’로 시작하는 거래 - 취소/반품율 분석 흐름: 결제 → 취소/반품 분석
- 데이터 타입
- 데이터 헤드
❓ 월별 주문 수는 어떻게 변동되었나요?(Month별 집계)
연월 추출하는 2가지 방법
1. LEFT
- 바로 LEFT 함수는 문자열에서 가능한데 InvoiceDate가 TIMESTAMP 타입이여서 에러가 뜸
- CAST 함수를 활용하여 STRING 문자열로 바꾸고 연월 7자리를 추출할 수 있음
SELECT InvoiceNo, LEFT(CAST(InvoiceDate AS STRING), 7)
FROM `day1.onlineretail`
2. FORMAT_TIMESTAMP
SELECT InvoiceNo, FORMAT_TIMESTAMP("%Y-%m", InvoiceDate)
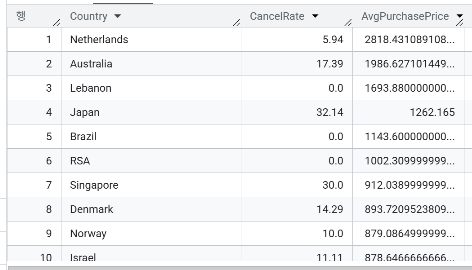
FROM `day1.onlineretail`❓ 나라별로 전체 주문 대비 취소율을 계산하고, 취소율이 가장 높은 국가는 어디인지 확인하세요. 앞의 결과에 추가로, 나라별 평균 주문 금액도 함께 계산하여 비교해보세요.
WITH OrderProcessed AS (
SELECT Country, InvoiceNo, Indicator, SUM(PurshasePrice) AS TotalPrice
FROM (
SELECT Country, InvoiceNo, StockCode, Quantity*UnitPrice AS PurshasePrice, CASE WHEN InvoiceNo LIKE 'C%' THEN 1 ELSE 0 END AS Indicator
FROM `day1.onlineretail`
) AS RawData
GROUP BY Country, InvoiceNo, Indicator
)
SELECT Country, ROUND(SUM(Indicator) / COUNT(DISTINCT InvoiceNo) * 100, 2) AS CancelRate, AVG(TotalPrice) AS AvgPurchasePrice
FROM OrderProcessed
GROUP BY Country
ORDER BY AvgPurchasePrice DESC
💡 해당 데이터 결과로 어떤 분석을 할 수 있을까?
- 취소율이 높은 국가를 판별하여 배송 품질을 높이거나, 제품 설명을 보강하거나, 맞지 않는 사이즈나 색상 문제가 있다는 가설을 세웠을 때 그 가설을 검증하거나 등 사용될 수 있음
- 평균 금액이 높은 국가일 경우 고가의 상품을 타겟팅 할 수도 있음
- 네덜란드 같은 경우는 고객의 평균 구매 금액이 높으니 고가의 상품을 팔 수 있겠다. 라는 전략을 세울 수 있음
- 특정 국가에 타겟팅을 하고 싶을 때 문제 진단을 위한, 혹은 문제 진단의 우선순위를 보기 위한, 구매력을 가늠해 볼 수 있음
❓ 가장 취소율이 높은 상품은 무엇인가요? (상품 취소율 = 취소된 수량 / 총 주문 수량)
취소율은?
- 현재 데이터에서 취소 상품은 InvoiceNo 앞에 C가 붙어있으며, Quantity 수량이 전부 음수로 되어있음
- 총 주문 수량 = 주문된 Quantity 수량 + 취소된 Quantity 수량(음수를 양수로 바꿔야함)
WITH RawData AS (
SELECT InvoiceNo,
StockCode,
Description,
CASE WHEN Quantity < 0 THEN -1*Quantity ELSE Quantity END AS FixedQuantity,
CASE WHEN InvoiceNo LIKE 'C%'THEN 1 ELSE 0 END AS Indicator
FROM `day1.onlineretail`
)
SELECT StockCode, Description, ROUND(SUM(FixedQuantity*Indicator) / SUM(FixedQuantity)*100, 2)
FROM RawData
GROUP BY StockCode, Description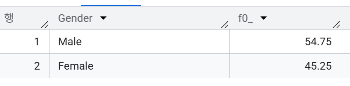
💡 해당 데이터 결과로 어떤 분석을 할 수 있을까?
- 어떤 상품이 결국 전체 판매량 대비 많이 취소가 되었는가
- 100% 취소율을 가진 상품들은 실제 상품의 품질이 나쁜지, 제품의 상세페이지와 실제 제품이 불일치하는지, 배송오류가 일어난건지 역으로 트래킹해서 문제 진단을 할 수 있음
- 취소율이 높은 상품은 결국 CS 클레임이 많을 수 있어 고객들의 불만을 분석해 볼 수도 있음
- 이 상품들을 상세하게 보았을 때 사진이나 설명 사이즈표가 잘 나와있지 않다면 개선 해야할 우선순위 상품인지 파악 가능
- 재고 운영 전략을 세울 때도 취소율이 많은 상품들은 재입고 수량을 보수적으로 짜거나 다음 달부터는 판매를 종료하거나 앞으로의 재고 운영의 효율을 높이는 방안을 세울 수 있음
2. Customer Segmentation Classification - 상품 추천 전략 수립을 위한 유저 세그멘테이션
한 자동차 회사는 기존 제품(P1~P5)을 새로운 시장에 출시할 계획을 세우고, 사전 조사를 통해 이 시장이 기존 시장과 유사한 특성을 가지고 있다는 점을 확인했습니다. 기존 시장에서는 고객을 A, B, C, D 네 개의 세그먼트로 분류한 뒤, 각 세그먼트에 맞춘 마케팅 전략을 적용해 좋은 성과를 거둔 경험이 있습니다. 이번에는 새롭게 확보한 잠재 고객(Test Dataset)에게도 동일한 전략을 적용하기 위해, 기존의 고객들이 어떠한 기준으로 분류되었는지를 확인하고자 합니다. 이 데이터는 그 예측 모델을 구축하고, 세그먼트별 맞춤 전략을 수립하는 데 활용됩니다.
📌 학습 목적
고객 데이터를 기반으로 각 세그먼트의 주요 특성을 파악하고, SQL을 활용해 의미 있는 인사이트를 도출함으로써 세그먼트별 맞춤 마케팅 전략을 수립하는 과정을 학습하는 데 목적이 있습니다. 주어진 분류 기준뿐만 아니라 다양한 기준을 스스로 설정해 고객을 재세분화해보며, 실제 비즈니스 환경에서의 전략 수립 과정에 대한 이해도를 높이는 것이 핵심입니다.
→ 우리는 기존 시장(Train Dataset)의 고객 데이터를 분석하고, A, B, C, D 세그먼트별 고객 특성을 파악하고 나아가 주어진 분류 기준 외에도 다양한 기준을 적용해 고객을 다시 세분화해보고, 그에 맞는 타겟 전략을 직접 수립해보는 활동을 해보자.
📌 주요 개념
| 컬럼명 | 설명 |
|---|---|
| ID | 고객 고유 ID |
| Gender | 고객의 성별 |
| Ever_Married | 고객의 혼인 여부 |
| Age | 고객의 나이 |
| Graduated | 고객의 대학 졸업 여부 |
| Profession | 고객의 직업 |
| Work_Experience | 고객의 경력 (년 단위) |
| Spending_Score | 고객 소비 성향 점수 |
| Family_Size | 고객을 포함한 가족 구성원 수 |
| Var_1 | 익명 처리된 고객 분류 항목 |
| Segmentation | (타겟) 고객이 속한 세그먼트 (A,B,C,D 중 하나) |
| - 데이터 타입 |
- 데이터 헤드

📌 데이터 EDA 1
- 전체 고객 수는 몇명? 8068명
- 성별 구성비는?
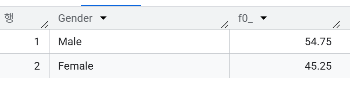
- 고객의 평균 나이는? 43.46세
❓ 결혼 여부 (Ever_Married)가 "Yes"인 고객은 몇 명인가요? 전체 대비 비율은 어떻게 되나요?
- 일단 Ever_Married 해당 컬럼을 보면 BOOLEAN 타입으로 true, false 값으로 이루어져 있음
- BOOLEAN 타입은 문자열처럼
Ever_Married = ‘true’형식으로 조건을 입력하면 에러가 남 Ever_Married IS true:IS활용,‘’따옴표도 빼야함
WITH RawData AS(
SELECT ID, Gender, Ever_Married,
CASE WHEN **Ever_Married IS true** THEN 1 ELSE 0 END AS Indicator
FROM `day1.recommend`
)
SELECT SUM(Indicator) AS MarriedNumber,
ROUND(SUM(Indicator) / COUNT(Indicator) * 100, 2) AS MarriedPercentage
FROM RawData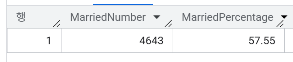
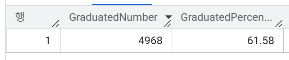
- 대학을 졸업한 (Graduated = "Yes") 고객의 비율은 얼마인가요?
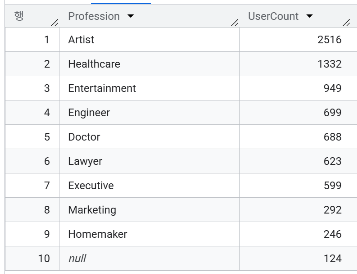
- 가장 많은 고객이 속한 직업군은 무엇인가요?
- Segmentation이 "A"인 고객의 평균 나이는 몇인가요?
📌 데이터 EDA 2
- 직업별 평균 소비 점수(Spending_Score)의 분포를 계산했을 때, High의 비율이 가장 높은 직업군은 어디인가요?
WITH ProcessedData AS (
SELECT ID, Profession, Spending_Score,
CASE WHEN Spending_Score = 'Low' THEN 1 ELSE 0 END IsLow,
CASE WHEN Spending_Score = 'Average' THEN 1 ELSE 0 END IsAvg,
CASE WHEN Spending_Score = 'High' THEN 1 ELSE 0 END IsHigh
FROM `day1.recommend`
)
SELECT Profession,
ROUND(SUM(IsLow)/COUNT(ID),2) AS LowNum,
ROUND(SUM(IsAvg)/COUNT(ID),2) AS AvgNum,
ROUND(SUM(IsHigh)/COUNT(ID),2) AS HighNum
FROM ProcessedData
GROUP BY Profession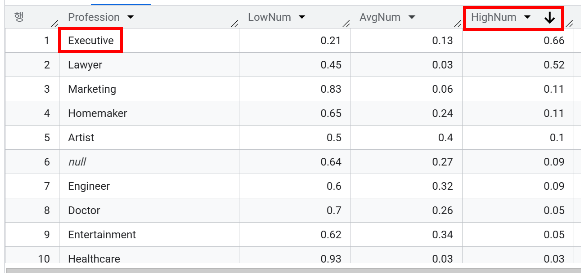
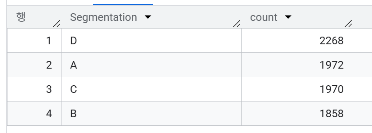
- 세그먼트 A, B, C, D 에 속한 고객 수는 각각 몇이며, 고객 수가 가장 많은 그룹은 어디인가요?
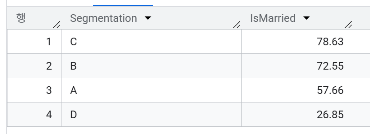
- 세그먼트 별 Ever_Married = "Yes"의 비율이 어떻게 다른가요? 두드러지는 트렌드가 있나요?
- 세그먼트와 Spending_Score 별 고객 분포를 확인했을 때 두드러지는 트렌드가 있나요? Spending_Score = "High"가 가장 많이 분포해 있는 세그먼트는 어디이며 "Average", "Low"가 가장 많이 분포해 있는 세그먼트는 어디인가요?
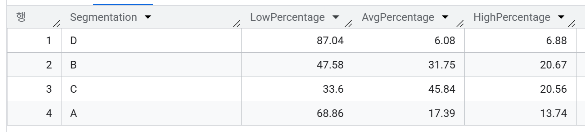
- 각 세그먼트 별 평균 나이가 어떻게 되나요?
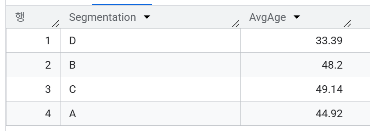
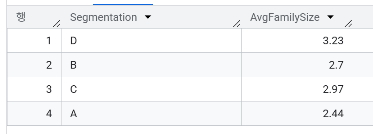
- 평균 가족 크기
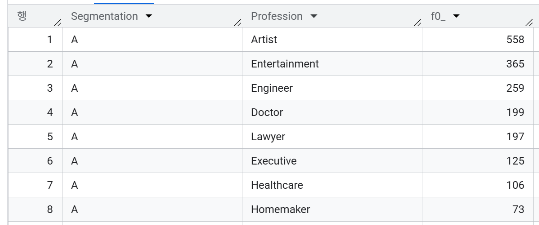
- 가장 빈도 높은 직업군 Top3
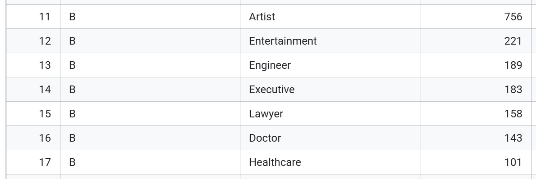
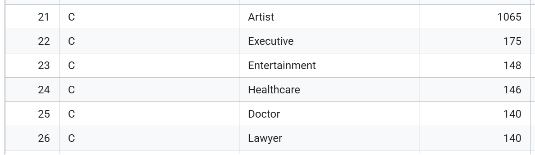
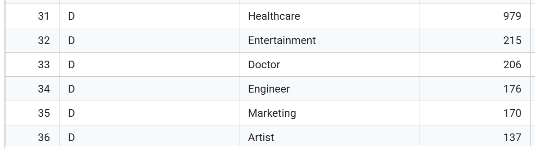
- 이제 각 그룹 별 퍼소나를 표현해보겠습니다. 각 그룹별 평균 나이, 결혼을 한 비율, 가장 빈도가 높은 직업(Profession) Top 3, 소비점수(Spending_Score) 비율 (ex. 1:2:3), 평균 Family_Size를 분석하여 아래 표를 채워넣어주세요.
| Group A | Group B | Group C | Group D | |
|---|---|---|---|---|
| 결혼 비율 | 57.66% | 75.55% | 78.63% | 26.85% |
| 평균 나이 | 45 | 48 | 49 | 33 |
| 소비 점수의 비율 (Low:Average:High) | 69:17:14 | 48:32:21 | 34:46:21 | 87:6:7 |
| 가장 빈도 높은 직업군 Top3 | Artist, Entertainment, Engineer | Artist, Entertainment, Engineer | Artist, Executive, Entertainment | Healthcare, Entertainment, Doctor |
| 평균 가족 크기 | 2.44 | 2.7 | 2.97 | 3.23 |
분석 결과 및 제안
- 이를 기반으로 "30대 미혼 Marketing" 종사자가 신규 고객으로 등록된 경우, 어느 세그먼트의 마케팅 전략을 수행하는 것이 좋을까요?
- Group D를 추천할 것 같습니다. 연령층도 비슷하고 Marketing 종사자도 Group D에서는 TOP5에 있고 다른 그룹에서는 굉장히 낮게 분포되어 있었습니다. 가장 비슷한 퍼소나가 있는 Group D 마켓팅 전략을 활용하면 좋을 것 같습니다.
'IT' 카테고리의 다른 글
| SQL with 빅쿼리 - 유저 행동 변화 분석 및 오프라인 매장 분석 (0) | 2026.04.25 |
|---|---|
| SQL with 빅쿼리 - 마케팅 캠페인 성과분석 (0) | 2026.04.24 |
| SQL with 빅쿼리 - PV, UV, ARPU, ARPPU, AARRR, 리텐션 분석 (1) | 2026.04.23 |
| SQL with 빅쿼리 - WITH문, WHERE문, 순위함수, 집계함수, 그룹함수 (0) | 2026.04.23 |
| SQL with 빅쿼리 - 집계함수, 그룹함수, 기본키(Primary Key), 외래키(Foreign Key), 조인, 서브쿼리 (0) | 2026.04.20 |


