1. A/B Testing Data - 신규 기능 출시 전후의 유저 행동 변화 분석
📌 학습 목적
이 실습의 목표는 A/B 테스트 데이터를 활용하여 신규 기능이 사용자 행동에 미친 영향을 분석하는 것입니다. 전환율(Conversion Rate) 비교를 통해 그룹 간 성과 차이를 정량적으로 평가하며, 궁극적으로 신규 기능이 실제 비즈니스 성과에 긍정적 영향을 주었는지를 판단하는 데이터 기반 의사결정 역량을 강화하는 것을 목표로 합니다.
📌 주요 개념
이 데이터는 신규 기능(웹페이지)의 효과를 측정하기 위해 실시한 A/B 테스트 결과를 담고 있습니다. 사용자는 무작위로 기존 페이지(old_page) 또는 신규 페이지(new_page) 중 하나에 배정되었으며, 그 결과 전환(가입, 구매 등)이 발생했는지를 converted 컬럼으로 기록합니다.
| 컬럼명 | 설명 |
|---|---|
| user_id | 사용자 고유 ID |
| timestamp | 페이지를 본 시점 (시간 정보 포함) |
| group | 사용자가 배정된 그룹 (control or treatment) |
| landing_page | 해당 사용자가 본 페이지 종류 (old_page, new_page) |
| converted | 전환 여부 (1=전환함, 0=전환하지 않음) |
- 데이터 타입
- 데이터 헤드
📌 A/B test란?
- 두 가지 버전(A와 B)을 사용자에게 무작위로 보여주고 어떤 것이 더 좋은 결과를 만드는지 비교하는 실험 방법
- 제품 개선, 마케팅, UX 개선 등에 사용
- 그룹 간 전활율 비교, 시간 흐름에 따른 변화 분석(날짜별 전환율 추이, 적응 곡선 파악 등), 세그먼트 분석(나이, 지역, 기기 종류 등)
A/B 테스트 진행 시 고려할 점
1️⃣ 명확한 가설 설정 (Hypothesis)
- 실험의 목적과 가설을 명확하게 정의해야 함
2️⃣ 핵심 지표(KPI) 정의
- 실험 성공 여부를 판단할 측정 지표를 미리 정해야 함
- 전환율, 클릭률, 체류 시간 등 핵심 성과지표(KPI)를 실험 시작 전에 명확히 설정
3️⃣ 사용자 랜덤 분배 (Randomization)
- 두 그룹의 사용자 특성이 비슷해야 결과가 공정하기 때문에 사용자를 랜덤하게 그룹에 배정해야 함
4️⃣ 충분한 샘플 크기 (Sample Size)
- 데이터가 충분하지 않으면 통계적으로 의미 있는 결과를 얻기 어렵기 때문
5️⃣ 실험 기간 설정
- 실험 기간이 너무 짧으면 외부 요인의 영향을 받을 수 있음
- 요일 효과, 시즌 효과, 프로모션 등의 영향을 덜 받도록 적절한 기간 유지
6️⃣ 한 번에 하나의 변수만 변경
- 여러 요소를 동시에 바꾸면 어떤 변화가 결과를 만들었는지 알 수 없음
7️⃣ 통제 변수(Control for Confounding)
- 실험 외에 영향을 줄 수 있는 다른 요인을 동일하게 유지
A/B 테스트 진행 과정
- 가설 설정
- 버튼 색을 빨간색으로 바꾸면 클릭률이 증가할 것이다.
- 사용자 랜덤 분배
- 두 그룹 특성을 동일하게 만들기 위해 무작위 할당해야함
- 실험 실행
- 실험 외 모든 조건을 동일하게 적절한 기한을 유지하며 두 버전을 동시에 운영
- 결과 측정
지표 의미 CTR 클릭률 Conversion Rate 구매 전환율 Retention 재방문율 Revenue 매출 - 통계적 유의성 검정
- 단순 차이가 아니라 통계적으로 의미 있는 차이인지 확인
- z-test, t-test, chi-square test 등을 통해 결과의 신뢰성 확보
- z-test: 전환율 비교 (비율)
- t-test: 평균 값 비교 (체류 시간, 구매액 등)
- chi-square test: 범주형 변수 간 독립성 검정
A/B-Test Calculator - Power & Significance - ABTestGuide.com
📌 데이터 EDA
- 전체 사용자 수는? 294,478명
- 날짜별 유저 수는?
WITH ProcessedData AS (
SELECT user_id, FORMAT_DATE('%Y-%m-%d', timestamp) AS TestDate
FROM `day3.abtest`
)
SELECT TestDate, COUNT(user_id) AS UserCount
FROM ProcessedData
GROUP BY TestDate
ORDER BY TestDate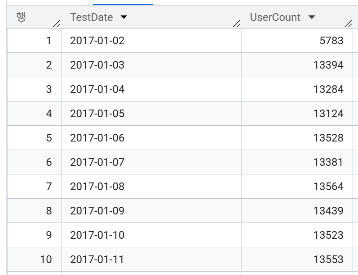
- Control 그룹과 Treatment 그룹은 각각 몇명?
SELECT `group`, COUNT(user_id) AS UserCount
FROM `day3.abtest`
GROUP BY `group`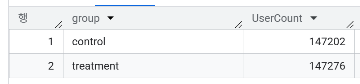
group 컬럼 명은 키워드로 사용이 많이 되어 group 이렇게 써줘야함
- 랜딩 페이지별로 몇 번씩 노출되었는지?
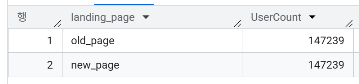
- 전체 전환율(전체 사용자 중 converted = 1인 비율)은 얼마인가? 11.97%
- Control 그룹인데 new_page를 본 사용자 수는 몇 명인가?(예외케이스) 1928명
- Treatment 그룹인데 old_page를 본 사용자 수는 몇 명인가?(예외케이스) 1965명
- 이상 케이스를 제외한 사용자 수는 몇명인가? 앞으로의 분석은 이상 케이스를 제외한 사용자들만을 대상으로 진행해보자 290,585명
- 그룹별 전환율은 각각 몇 %인가? 그룹별 전체 사용자 수, 전환 수, 그리고 전환율을 분석해보자
WITH ProcessedData AS (
SELECT *
FROM `day3.abtest`
WHERE (`group` = 'treatment' AND landing_page = 'new_page')
OR (`group` = 'control' AND landing_page = 'old_page')
)
SELECT `group`,
COUNT(*) AS TotalUsers,
SUM(converted) AS ConvertedUsers,
ROUND(SUM(converted)/ COUNT(*) * 100, 2) AS ConversionRate
FROM ProcessedData
GROUP BY `group`
- 이 차이는 통계적으로 유의한 차이가 있는가? 유의미 하지 않다.
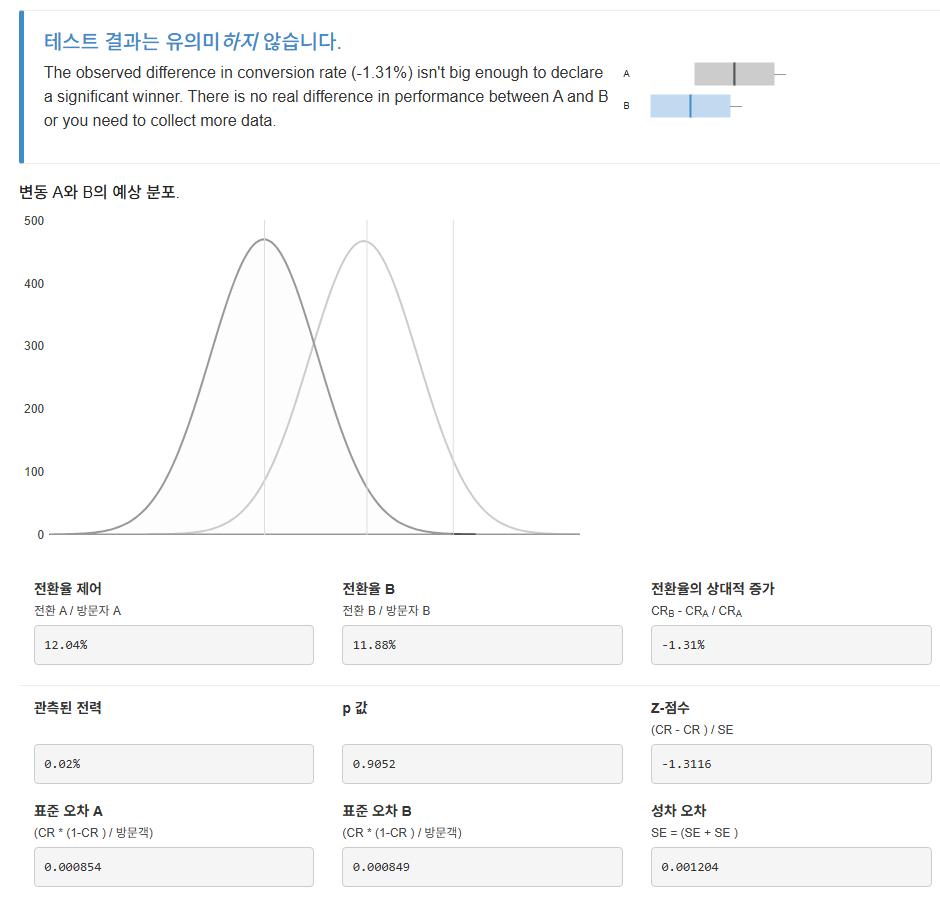
통계적으로 유의미한 수치 차이가 아니기 때문에 이 수치의 차이는 우연에 의해 일어났을 가능성이 높다.
새로운 new_page는 old_page와 비교했을 때 아무런 차이가 없다.
2. 오프라인 매장 분석: 위치별 매출 및 트래픽 비교
📌 학습 목적
이 실습의 목표는 리테일 데이터를 기반으로 매장 판매 성과를 분석하고, 이를 통해 수익성 향상 방안을 도출하는 것입니다. 판매 트렌드와 경쟁 요인을 반영한 데이터 분석을 통해 매장의 현재 위치를 진단하고, 전략 수립에 필요한 인사이트를 도출하는 과정을 실습합니다. 특히 이번 실습에서는 두 개의 테이블을 JOIN하여 분석하는 기법에 중점을 두고, 다양한 데이터를 통합적으로 해석하는 연습을 진행할 예정입니다.
📌 주요 개념
- Rossmann 데이터셋은 유럽 7개국에서 3,000개 이상의 드럭스토어를 운영하는 기업에서 제공한 데이터
- 2015년 1월 1일부터 2015년 7월 31일까지의 데이터
- store.csv
| 컬럼명 | 설명 |
|---|---|
| Store | 고유한 매장 ID |
| StoreType | 4가지 다른 매장 유형 (a,b,c,d) |
| Assortment | 제품 구성 수준 (a=기본, b=추가, c=확장) |
| CompetitionDistance | 가장 가까운 경쟁 매장까지의 거리(미터 단위) |
| CompetitionOpenSinceMonth | 가장 가까운 경쟁 매장이 개점한 월 |
| CompetitionOpenSinceYear | 가장 가까운 경쟁 매장이 개점한 연도 |
| Promo2 | 일부 매장에서 진행되는 프로모션 |
| Promo2SinceWeek | 매장이 Promo2에 참여하기 시작한 주 |
| Promo2SinceYear | 매장이 Promo2에 참여하기 시작한 연도 |
| PromoInterval | Promo2가 시작되는 연속적인 기간 (ex. Feb, May, Aug, Nov 는 매장이 매년 2, 5, 8, 11월에 프로모션을 시작함을 의미) |
- store 데이터 타입
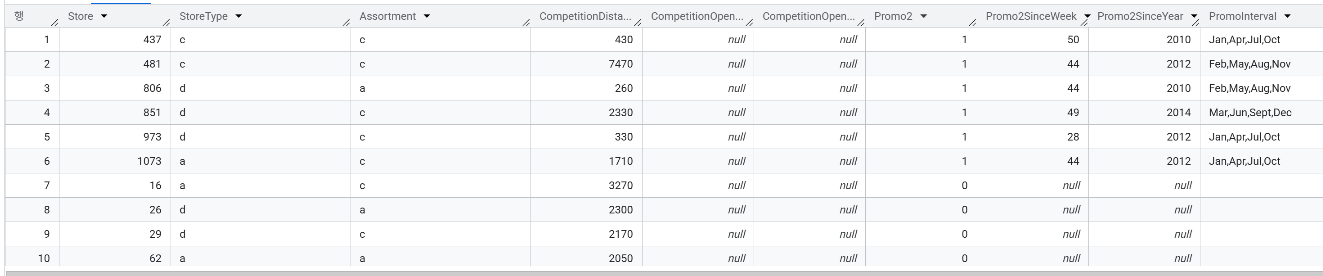
- store 데이터 헤드
- sales.csv
| 컬럼명 | 설명 |
|---|---|
| Store | 고유한 매장 ID |
| DayOfWeek | 무슨 요일에 대한 데이터인지 0~6으로 표현 |
| Date | 몇일자에 대한 세일즈 데이터인지 파악 |
| Sales | 특정 날의 매출액 |
| Customers | 특정 날 방문한 고객 수 |
| Open | 매장 개점 여부를 나타내는 지표 (0 = 휴점, 1 = 개점) |
| Promo | 특정 날 매장에서 프로모션을 진행 중인지 여부 |
- sales 데이터 타입
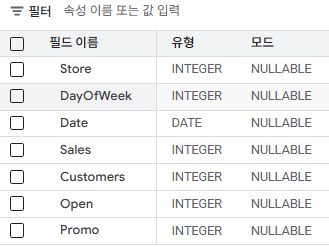
- sales 데이터 헤드
판매/매출 데이터 분석의 예시
- 시즌별 판매 트렌드 예측
- 고객 행동 분석을 통한 기회 포착
- 신제품 출시 타이밍 최적화
- 지역별 시장 기회 탐색
📌 데이터 EDA
- 전체 매장 수는? 1115개
- 전체 평균 매출은? 5878
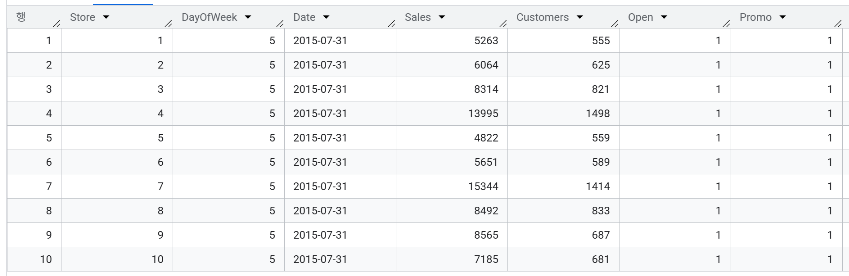
- 매장별 평균 고객 수는?
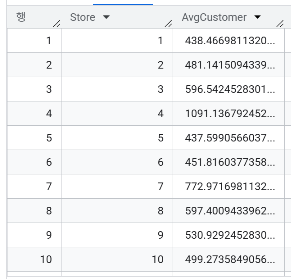
- 고유한 StordType에는 어떤 유형들이 있는가?
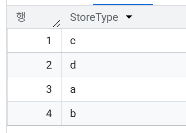
- 고유한 Assortment에는 어떤 유형들이 있는가?
- 매장 293의 정기 휴점 요일은 언제인가? 일요일
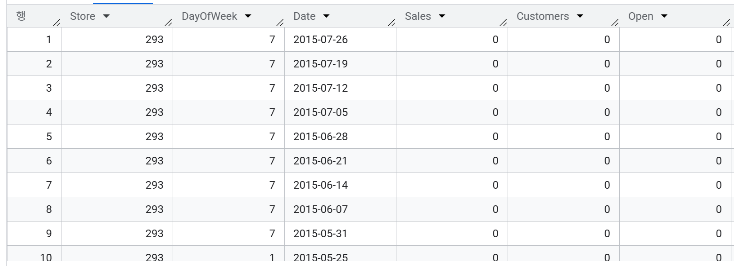
- 매장 293의 매출이 가장 높게 나오는 요일은 언제인가? 월요일
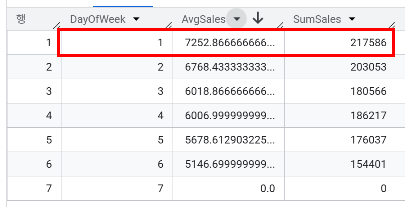
- 매장 293의 매출이 가장 높게 나왔던 일자는 몇일인가? 이것은 평균 매출이랑 얼마나 차이가 나는가?
SELECT Date, Sales, Sales - (SELECT AVG(Sales) FROM `day3.sales` WHERE Store = 293) AS Diff
FROM `day3.sales`
WHERE Store = 293
ORDER BY Sales DESC
- 경쟁사와의 평균 거리는? 평균 : 5,404m, 최소 : 20m, 최대 : 75,860m
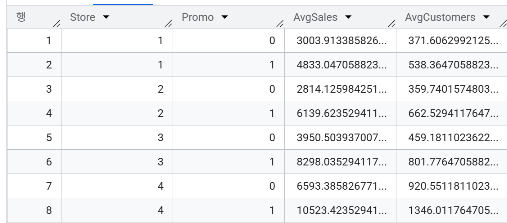
- sales 테이블에서 Promo 진행 여부가 전체적인 매출과 고객 방문 향상에 도움이 되었나요?
- 2015년 상반기(1월~6월) 누적 매출이 가장 높은 TOP 3 매장은 어디인가?
SELECT Store, SUM(Sales) AS AvgSales
FROM `day3.sales`
WHERE Date BETWEEN '2015-01-01' AND '2015-06-30'
GROUP BY Store
ORDER BY SUM(Sales) DESC
LIMIT 3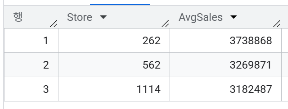
- 각 Assortment 유형에 해당되는 매장의 평균 매출(Sales)과 평균 고객 수(Customers)를 계산하고, 이를 통해 어떤 Assortment 유형의 매장이 가장 규모가 크고 고객이 많이 모이는지 확인해보자
WITH ProcessedSales AS (
SELECT Store, AVG(Sales) AS AvgSales, AVG(Customers) AS AvgCustomers
FROM `day3.sales`
GROUP BY Store
)
SELECT Assortment,
AVG(AvgSales) AS AverageSales,
AVG(AvgCustomers) AS AverageCustomers
FROM `day3.store` AS store
JOIN ProcessedSales AS pr
ON store.Store = pr.Store
GROUP BY Assortment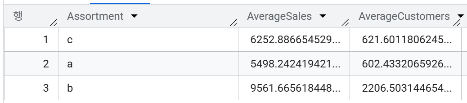
- 각 매장(Store)별로 평균 매출(Sales)과 평균 고객 수(Customers)를 먼저 계산한 뒤, 이를 기반으로 StoreType(매장 유형)별로 매장을 그룹화하여 다음 항목들을 구해보자
- StoreType별 매장 수
- StoreType별 평균 매출
- StoreType별 평균 고객 수
- 고객 1인당 평균 매출 (평균 매출 ÷ 평균 고객 수)
- 이 분석을 통해 어떤 StoreType이 가장 높은 매출 규모와 고객당 매출 효율을 보이는지 파악해보는 것이 목표입니다.
WITH ProcessedStore AS (
SELECT Store, AVG(Sales) AS AvgSales, AVG(Customers) AS AvgCustomers
FROM `day3.sales`
GROUP BY Store
)
SELECT StoreType,
COUNT(*) AS StoreCount,
AVG(AvgSales) AS AverageSales,
AVG(AvgCustomers) AS AverageCustomers,
AVG(AvgSales/AvgCustomers) AS AvgSalesPerCustomer
FROM `day3.store` AS store
JOIN ProcessedStore AS pr
ON store.Store = pr.Store
GROUP BY StoreType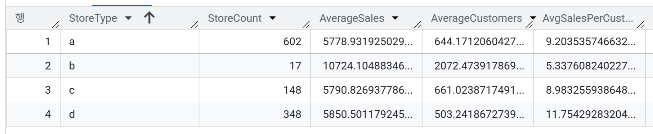
- 경쟁사와의 거리가 100m 미만인 매장과 그렇지 않은 매장을 비교하여, 근처(<100m)에 경쟁 매장이 있으면 고객 당 평균 매출에 차이가 발생하는지를 확인해보자
WITH ProcessedSales AS (
SELECT Store, AVG(Sales) AS AvgSales, AVG(Customers) AS AvgCustomers
FROM `day3.sales`
GROUP BY Store
),
ProcessedStore AS (
SELECT store.Store, CASE WHEN CompetitionDistance < 100 THEN 'CompetitorClose' ELSE 'CompetitorFar' END AS Indicator
FROM `day3.store` AS store
)
SELECT Indicator, AVG(AvgSales/AvgCustomers) AS SalesPerCustomer
FROM ProcessedSales
JOIN ProcessedStore
ON ProcessedSales.Store = ProcessedStore.Store
GROUP BY Indicator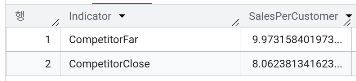
- 매장 770은 2015년 4월에 경쟁사가 100m 거리에 오픈했습니다. 월별 평균 매출과 평균 고객 수를 분석하여 경쟁사 오픈이 전체적인 매출에 영향을 미쳤는지, 매장 770의 데이터를 기반으로 검정을 해보자.
→ 경쟁사 4월 오픈 기준으로 전체적인 매출과 평균 고객 수가 감소한걸 확인 할 수 있었음
SELECT FORMAT_DATE('%Y-%m', Date) AS Month, AVG(Sales) AS AvgSales, AVG(Customers) AS AvgCustomers
FROM `day3.sales`
WHERE Store = 770
GROUP BY FORMAT_DATE('%Y-%m', Date)
ORDER BY FORMAT_DATE('%Y-%m', Date) ASC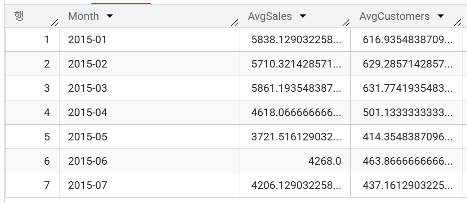
'IT' 카테고리의 다른 글
| SQL with 빅쿼리 - Amazon 데이터셋 기반 추천 시스템 설계 (1) | 2026.04.26 |
|---|---|
| SQL with 빅쿼리 - 마케팅 캠페인 성과분석 (0) | 2026.04.24 |
| SQL with 빅쿼리 - 이커머스 전환율 분석 및 상품 추천 전략 수립 (1) | 2026.04.23 |
| SQL with 빅쿼리 - PV, UV, ARPU, ARPPU, AARRR, 리텐션 분석 (1) | 2026.04.23 |
| SQL with 빅쿼리 - WITH문, WHERE문, 순위함수, 집계함수, 그룹함수 (0) | 2026.04.23 |



