1. Customer Churn Dataset - 유저 리텐션 분석 및 이탈 예측
고객 이탈(Customer Churn)이란 고객이 기업이나 서비스 제공자와의 관계 또는 구독을 중단하는 현상을 의미합니다. 이는 일정 기간 동안 고객이 제품이나 서비스를 더 이상 이용하지 않게 되는 비율을 나타내며, 기업의 매출, 성장, 고객 유지율에 직접적인 영향을 미치는 중요한 지표입니다.
Churn 데이터셋에서는 'Churn'이라는 라벨이 해당 고객이 이탈했는지를 나타냅니다. 이탈한 고객은 더 이상 서비스를 이용하지 않기로 결정한 사람을 의미하며, 반대로 비이탈 고객은 여전히 서비스를 이용하며 기업과의 관계를 유지하고 있는 사람입니다.
📌 학습 목적
이 실습의 목적은 고객 이탈(Churn)과 리텐션(Retention)에 영향을 미치는 요인들을 분석하고, 이를 통해 잠재적 이탈 고객을 조기에 식별할 수 있는 인사이트를 도출하는 데 있습니다. 계약 형태, 사용 패턴, 고객 응대 이력, 지불 지연 등의 다양한 요인이 이탈률에 미치는 영향을 파악하고, 비즈니스 관점에서 실행 가능한 리텐션 전략 수립으로까지 확장하는 것이 핵심 목표입니다.
📌 주요 개념
- 총 440,882명의 고객 정보와 그에 해당하는 다양한 특성 및 이탈 여부 라벨이 포함
- 고객 이탈을 "예측"하는 머신러닝 모델을 학습시키기 위한 주요 자료로 활용
- 이탈 여부 라벨은 해당 고객이 이탈했는지(1) 또는 유지 중인지(0)를 나타냄
| 컬럼명 | 설명 |
|---|---|
| CustomerID | 고객 식별자(ID). 각 고객을 고유하게 구분하기 위한 값. |
| Age | 고객의 나이. 약 18세부터 65세까지 분포하며, 주요 연령대별 행동 차이를 파악할 수 있음. |
| Gender | 고객의 성별. 'Male', 'Female', 'Other' 값이 존재. |
| Tenure | 고객의 가입 기간(개월 단위). 장기 고객일수록 이탈 가능성이 낮을 수 있음. |
| Usage Frequency | 서비스 사용 빈도. 일 단위나 주 단위의 평균 이용 횟수로 해석되며, 충성도 판단의 핵심 지표. |
| Support Calls | 고객센터 문의 횟수. 문제를 자주 겪는 고객은 이탈 가능성이 높아질 수 있음. |
| Payment Delay | 지불 지연 일수. 정기 결제를 늦게 하거나 미루는 고객은 리스크 고객일 수 있음. |
| Subscription Type | 구독 유형. 예: Basic, Standard, Premium 등의 상품군으로 구성되어 있으며, 상품별 이탈률 차이를 분석할 수 있음. |
| Contract Length | 계약 기간. 'Monthly', 'Quarterly', 'Annual' 등으로 구성되며, 장기 계약일수록 이탈률이 낮을 수 있음. |
| Total Spend | 누적 지출 금액. 약 100~450,000까지 폭넓은 분포를 가지며, 고지출 고객은 유지 우선 대상. |
| Last Interaction | 마지막 고객 접촉 이후 경과일. 오래 접촉하지 않은 고객일수록 이탈 가능성이 높음. |
| Churn | 이탈 여부. 1은 이탈(서비스 중단), 0은 유지 중인 고객을 의미합니다. 예측 대상(label)로 활용됨. |
- 데이터 타입
- 데이터 헤드

📌 데이터 EDA 1
- 전체 고객 수는 몇명? 440832명
- 전체 고객 중 이탈한 고객(Churn=1)의 비율은 몇 %? 56.71%
# 1.
SELECT ROUND(SUM(Churn)/COUNT(DISTINCT CustomerID)*100, 2)
FROM `day2.churn`
# 2.
SELECT COUNT(CustomerID)/(SELECT COUNT(CustomerID) FROM `day2.churn` )
FROM `day2.churn`
WHERE Churn = 1
# 3.
SELECT SUM(Churn)/COUNT(Churn)
FROM `day2.churn`- 고객들의 평균 나이는? 39.37세
- 구독 상품(Subscription Type)별 고객 수는?
# 컬럼명에 띄어쓰기가 있으면 ``으로 묶어줘야 인식 가능
SELECT `Subscription Type`, COUNT(CustomerID)
FROM `day2.churn`
GROUP BY `Subscription Type`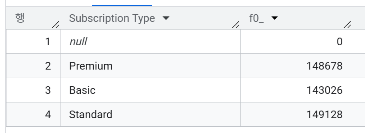
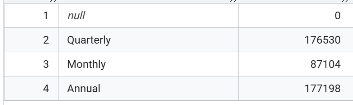
- 계약 기간(Contract Length)별 고객 수는? 특정 트렌드가 보임? 월간 < 분기별 < 연간
- 성별(Gender)의 비율은?
WITH ProcessedData AS (
SELECT CustomerID,
CASE WHEN Gender = 'Female' THEN 1 ELSE 0 END AS FemaleCount,
CASE WHEN Gender = 'Male' THEN 1 ELSE 0 END AS MaleCount
FROM `day2.churn`
)
SELECT ROUND(SUM(FemaleCount)/COUNT(CustomerID)*100, 2) AS FemalePercentage,
ROUND(SUM(MaleCount)/COUNT(CustomerID)*100 ,2) AS MalePercentage
FROM ProcessedData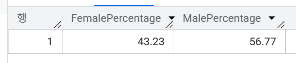
- 성별(Gender)별 이탈률은 각각 몇 %인가?
SELECT Gender, ROUND(SUM(Churn)/COUNT(CustomerID)*100, 2)
FROM `day2.churn`
GROUP BY Gender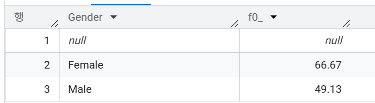
📌 데이터 EDA 2
- 구독 유형별 이탈율은?
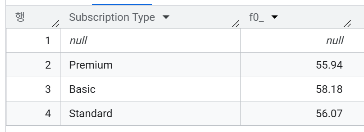
- 계약 기간별 이탈율은?
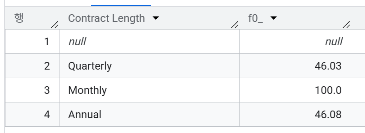
- 고객센터 문의 횟수가 많은 순으로 상위 10명의 이탈 여부 확인
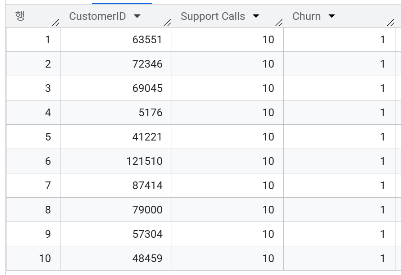
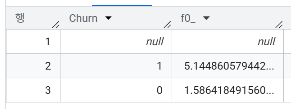
- 이탈 여부에 따른 평균 고객센터 문의 횟수는?
- 서비스 평균 사용 빈도(Usage Frequency)가 10 이하인 고객의 이탈율은?
SELECT ROUND(SUM(Churn)/COUNT(Churn)*100,2)
FROM `day2.churn`
WHERE `Usage Frequency` <= 10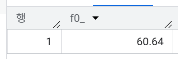
)
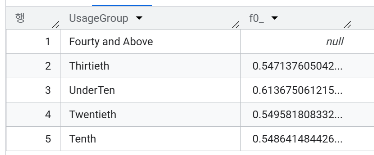
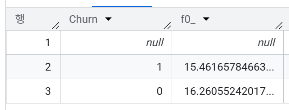
- 이탈 여부에 따른 평균 사용 빈도는? 특정 트렌드가 보이나요?
🚨 지불 지연이 평균 이상인 고객의 이탈율은?
# 에러!!!!!!!!!!!!!!!!!
SELECT SUM(Churn)/COUNT(Churn)*100
FROM `day2.churn`
WHERE `Payment Delay` >= AVG(`Payment Delay`)WHERE 절에는 집계함수를 쓸 수 없음!!!
# SQL 실행 순서! 작성 순서랑은 또 다름!
1. FROM
2. WHERE
3. GROUP BY
4. HAVING
5. SELECT
6. ORDER BYWHERE→ 행(row) 단위 필터AVG()→ 전체 데이터 집계 후 계산- 서브 쿼리로 집계 함수 가능함
# 올바른 쿼리문
SELECT SUM(Churn)/COUNT(Churn)*100
FROM `day2.churn`
WHERE `Payment Delay` >= (SELECT AVG(`Payment Delay`) FROM `day2.churn`)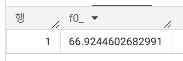
- 총 지출 금액이 하위 25%에 해당하는 고객의 이탈율은?
# 하위 25%
SELECT SUM(Churn)/COUNT(Churn)*100
FROM `day2.churn`
WHERE `Total Spend` <= (
SELECT DISTINCT PERCENTILE_CONT(`Total Spend`, 0.25) OVER () AS Spend25,
FROM `day2.churn`
)PERCENTILE_CONT : 연속형 백분위수(continuous percentile) 를 계산하는 함수( 25%, 50%, 75% 등 특정 퍼센트 위치의 값을 계산할 때 사용)
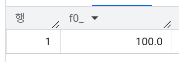
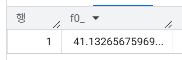
- 총 지출 금액이 상위 25%에 해당하는 고객의 이탈율은?
# 상위 25%
SELECT SUM(Churn)/COUNT(Churn)*100
FROM `day2.churn`
WHERE `Total Spend` >= (
SELECT DISTINCT PERCENTILE_CONT(`Total Spend`, 0.75) OVER () AS Spend75,
FROM `day2.churn`
)
2. Banking Marketing Dataset - 마케팅 캠페인 성과 분석
이 데이터셋은 포르투갈의 한 은행이 2008년부터 2010년까지 진행한 전화 기반 마케팅 캠페인 데이터를 담고 있습니다. 이 데이터셋은 고객이 정기예금 상품에 가입할지 여부를 예측하는 이진 분류 문제를 다루며, 마케팅 성과 분석 및 고객 행동 예측 모델링에 널리 활용됩니다.
📌 학습 목적
이 실습의 목적은 데이터를 기반으로 마케팅 캠페인의 효과를 평가하고, 고객의 특성과 행동 데이터를 분석하여 전환율(Conversion Rate)에 영향을 미치는 요인들을 파악하는 데 있습니다. 고객 세그먼트별 응답률을 비교하고, 직업, 나이, 교육 수준, 대출 여부, 연락 방식 등의 변수들이 캠페인 성과에 어떤 영향을 주는지 분석함으로써, 보다 정교하고 타겟팅된 마케팅 전략을 수립하는 역량을 기르는 것이 핵심입니다.
📌 주요 개념
- 예측 목표: 고객이 정기예금에 가입했는지 여부 (y: 'yes' 또는 'no')
- 정기예금 관련 캠페인 데이터
- 이번 실습에서 사용하지 않는 컬럼도 존재
| 컬럼명 | 설명 |
|---|---|
| age | 고객의 나이 |
| job | 직업 유형 |
| marital | 결혼 상태 |
| education | 교육 수준 |
| default | 신용 불량 여부 |
| balance | 평균 연간 계좌 잔액 (유로화 기준) |
| housing | 주택 대출 보유 여부 (yes, no) |
| loan | 개인 대출 보유 여부 (yes, no) |
| contact | 연락 수단 (cellular, telephone) |
| day | 마지막 연락 일 (1~31) |
| month | 마지막 연락 월 (may, jun, jul) |
| duration | 마지막 통화 지속 시간 (초 단위) |
| campaign | 현재 캠페인 동안 고객에게 연락한 횟수 |
| pdays | 이전 캠페인 이후 경과일 수 (999는 이전에 연락한 적 없음) |
| previous | 이전 캠페인에서 고객에게 연락한 횟수 |
| poutcome | 이전 마케팅 캠페인의 결과 |
| y | 정기예금 가입 여부 (yes, no) |
- 데이터 타입
- 데이터 헤드

)
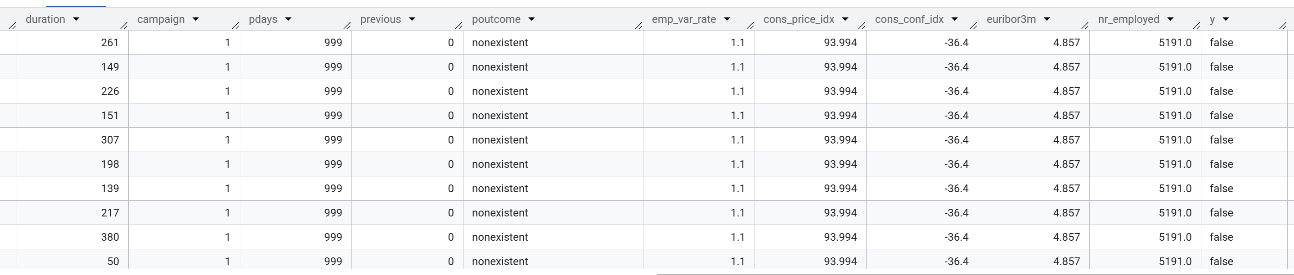
💡 활용 사례
- 마케팅 성과 분석: 캠페인 전략의 효과를 평가하고, 고객 세그먼트 별 반응을 분석하는 데 유용
- 고객 행동 예측: 고객의 특성과 이전 상호작용을 기반으로 향후 행동을 예측할 수 있음
- 이탈 예측 모델링: 고객의 이탈 가능성을 예측하여 선제적인 대응 전략을 수립하는 데 활용
📌 데이터 EDA 1
- 전체 고객 수는 몇 명? 41188명
- 전체 고객 중 정기 예금에 가입한 고객 수는 몇 명? 4640명
- 평균 나이는? 40.02세
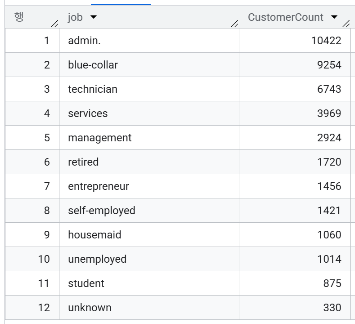
- job 컬럼 기준, 고객이 가장 많은 직업군은?
- job 컬럼 기준, 고객 수 대비 정기 예금 가입율은?
WITH ProcessedData AS (
SELECT job, CASE WHEN y IS true THEN 1 ELSE 0 END AS Indicator
FROM `day2.campaign`
)
SELECT job, ROUND(SUM(Indicator)/COUNT(*)*100,2) AS ConversionRate
FROM ProcessedData
GROUP BY job
ORDER BY ConversionRate DESC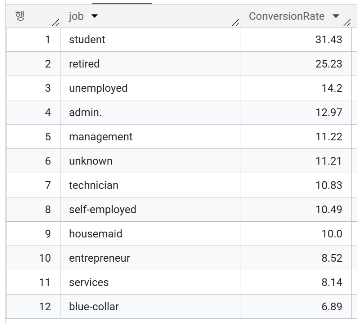
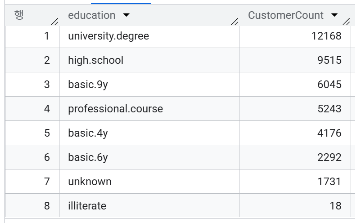
- 교육 수준에 따른 고객수는 어떠한 트렌드를 보이는가? 특별한 경향성이 보이진 않음
📌 데이터 EDA 2
- 전체 고객 중 정기예금 가입률은? 11.27%
# CASE WHEN THEN 사용
WITH ProcessedData AS (
SELECT CASE WHEN y IS true THEN 1 ELSE 0 END AS Indicator
FROM `day2.campaign`
)
SELECT ROUND(SUM(Indicator)/COUNT(*)*100,2) AS ConversionRate
FROM ProcessedData
# WHERE절 사용
SELECT ROUND(COUNT(*)/(SELECT COUNT(*) FROM `day2.campaign`)*100,2) AS ConversionRate
FROM `day2.campaign`
WHERE y IS true- 연락 수단 별 가입률은?
WITH ProcessedData AS (
SELECT contact, CASE WHEN y is true THEN 1 ELSE 0 END AS Indicator
FROM `day2.campaign`
)
SELECT contact, ROUND(SUM(Indicator)/COUNT(*)*100,2)
FROM ProcessedData
GROUP BY contact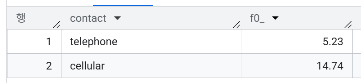
🚨 housing과 loan 대출 여부에 따른 가입률 차이는?
WITH ProcessedData AS (
SELECT housing, loan, CASE WHEN y is true THEN 1 ELSE 0 END AS Indicator
FROM `day2.campaign`
)
SELECT 'HOUSING' AS Category, housing AS Value, COUNT(*) AS CustomerCount, SUM(Indicator), ROUND(SUM(Indicator)/COUNT(*)*100,3) AS ConversionRate
FROM ProcessedData
GROUP BY housing
UNION ALL
SELECT 'LOAN' AS Category, loan AS Value, COUNT(*) AS CustomerCount, SUM(Indicator), ROUND(SUM(Indicator)/COUNT(*)*100,3) AS ConversionRate
FROM ProcessedData
GROUP BY loanUNION ALL : 위 아래 블럭을 붙여서 출력해줌
'HOUSING' AS Category : 카테고리라는 이름으로 행 하나 더 넣어줌
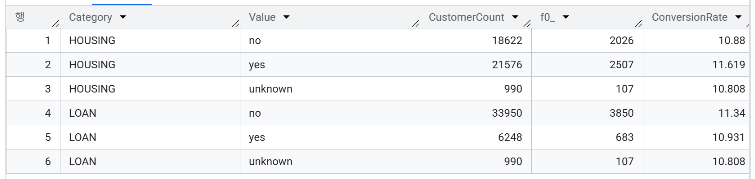
- HOUSING(주택 대출 보유 여부)
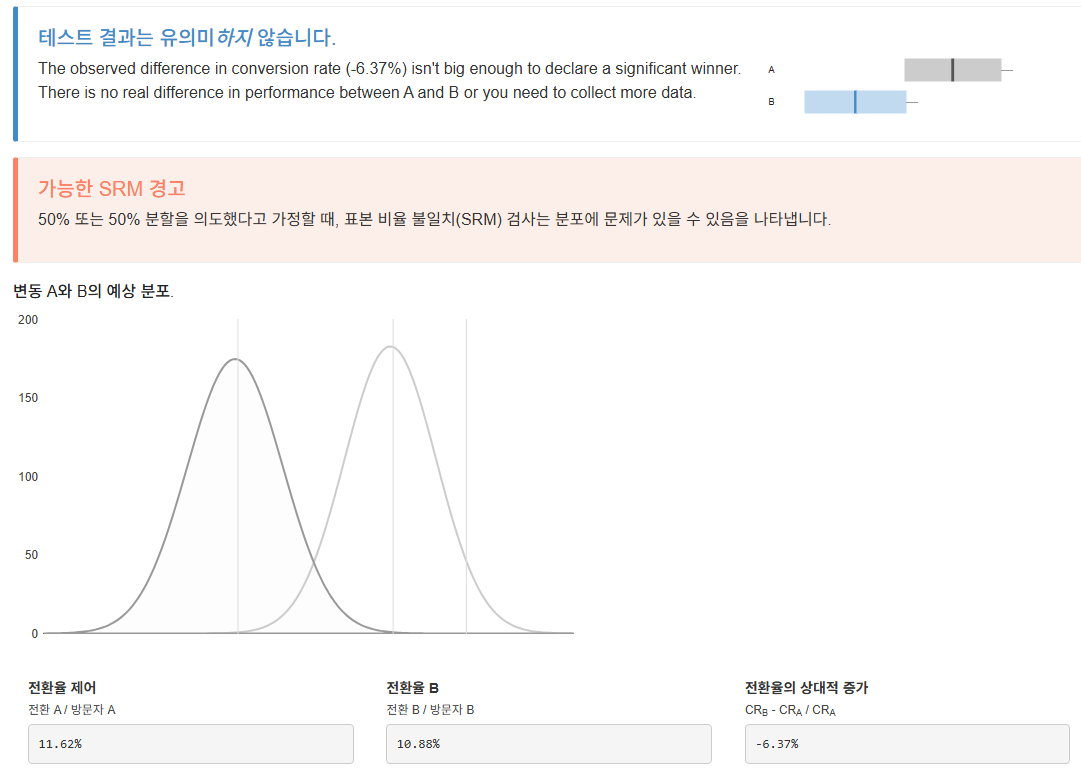
- LOAN(개인 대출 보유 여부)
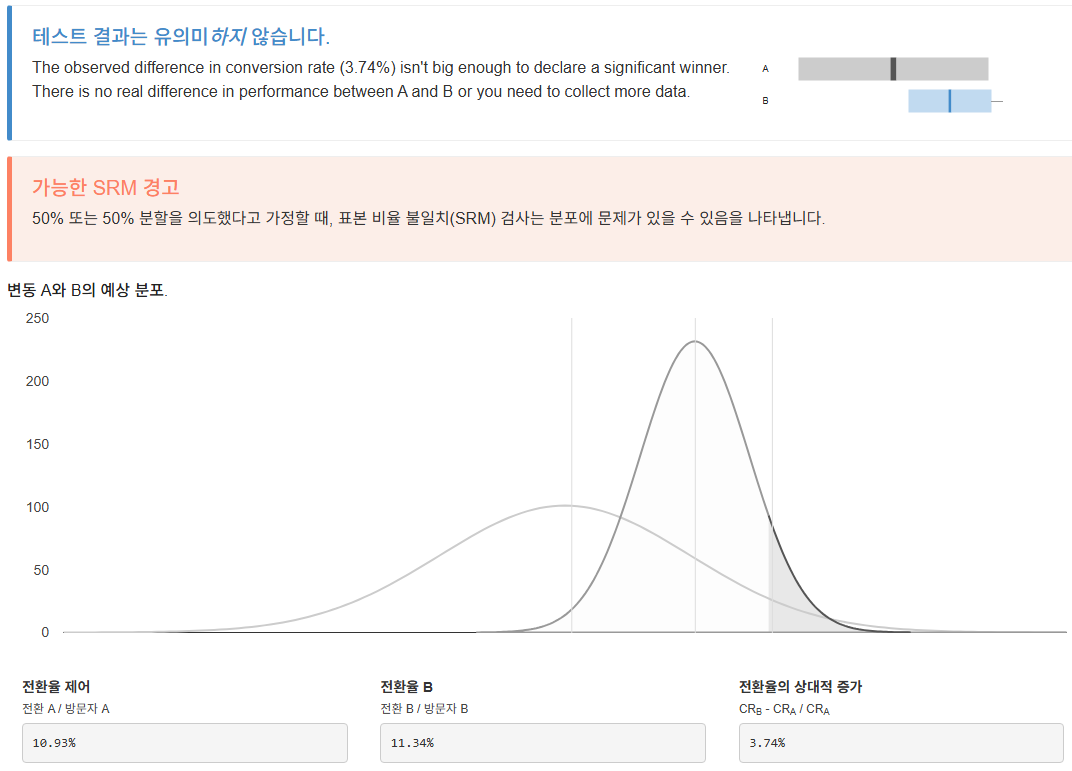
- 과거에 연락한 적이 있는 고객과 그렇지 않은 고객의 가입률 차이가 두드러지는가?
WITH ProcessedData AS (
SELECT pdays, CASE WHEN pdays = 999 THEN 'previous_N' ELSE 'previous_Y' END AS previousContact,
CASE WHEN y is true THEN 1 ELSE 0 END AS Indicator
FROM `day2.campaign`
)
SELECT previousContact, ROUND(SUM(Indicator)/COUNT(*)*100,2)
FROM ProcessedData
GROUP BY previousContact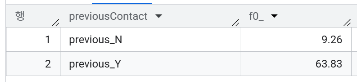
- 이전 캠페인 결과(poutcome)별 가입률은? 이전에 가입을 했던 고객들이 이번에도 가입할 확률이 높은가?
WITH ProcessedData AS (
SELECT poutcome, CASE WHEN y is true THEN 1 ELSE 0 END AS Indicator
FROM `day2.campaign`
WHERE poutcome IN ('failure','success')
)
SELECT poutcome, ROUND(SUM(Indicator)/COUNT(*)*100,2) AS ConversionRate
FROM ProcessedData
GROUP BY poutcome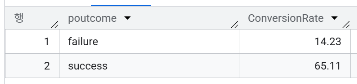
- 현재 캠페인 동안 각 고객에게 연락한 횟수가 정기예금 가입 여부에 영향을 미치고 있는가? 연락을 더 자주하는 것이 정기 예금 가입에 도움이 될까?
WITH ProcessedData AS (
SELECT CASE WHEN campaign <= 5 THEN 'Group1'
WHEN campaign > 5 AND campaign <= 10 THEN 'Group2'
WHEN campaign > 10 AND campaign <= 15 THEN 'Group3'
ELSE 'Group4' END CampignGroup,
CASE WHEN y is true THEN 1 ELSE 0 END AS Indicator
FROM `day2.campaign`
)
SELECT CampignGroup, ROUND(SUM(Indicator)/COUNT(*)*100,2) AS ConversionRate
FROM ProcessedData
GROUP BY CampignGroup
ORDER BY CampignGroup ASC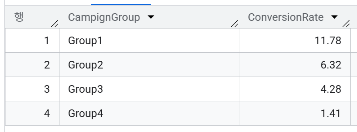
- 나이를 10살 단위로 구간화하여(20대, 30대, 40대) 연령대별 가입률을 분석했을 때, 가장 높은 가입률을 보이는 연령대는?
WITH ProcessedData AS (
SELECT CASE WHEN age < 20 THEN '0~19'
WHEN age BETWEEN 20 AND 29 THEN '20~29'
WHEN age BETWEEN 30 AND 39 THEN '30~39'
WHEN age BETWEEN 40 AND 49 THEN '40~49'
WHEN age BETWEEN 50 AND 59 THEN '50~59'
ELSE '60+' END AgeGroup,
CASE WHEN y is true THEN 1 ELSE 0 END AS Indicator
FROM `day2.campaign`
)
SELECT AgeGroup, ROUND(SUM(Indicator)/COUNT(*)*100,2) AS ConversionRate
FROM ProcessedData
GROUP BY AgeGroup
ORDER BY AgeGroup ASC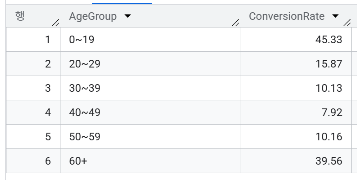
- 통화를 더 오래 할수록 고객의 가입률에 차이가 발생했는가? 통화 시간을 구간화하여 분석해보자
WITH ProcessedData AS (
SELECT duration, NTILE(4) OVER(ORDER BY duration) AS DurationGroup,
CASE WHEN y is true THEN 1 ELSE 0 END AS Indicator
FROM `day2.campaign`
)
SELECT DurationGroup, ROUND(SUM(Indicator)/COUNT(*)*100,2) AS ConversionRate
FROM ProcessedData
GROUP BY DurationGroup
ORDER BY DurationGroup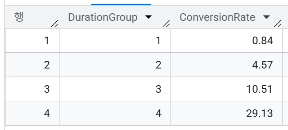
NTILE(N) : 데이터를 N개의 그룹으로 나누는 함수
'IT' 카테고리의 다른 글
| SQL with 빅쿼리 - Amazon 데이터셋 기반 추천 시스템 설계 (1) | 2026.04.26 |
|---|---|
| SQL with 빅쿼리 - 유저 행동 변화 분석 및 오프라인 매장 분석 (0) | 2026.04.25 |
| SQL with 빅쿼리 - 이커머스 전환율 분석 및 상품 추천 전략 수립 (1) | 2026.04.23 |
| SQL with 빅쿼리 - PV, UV, ARPU, ARPPU, AARRR, 리텐션 분석 (1) | 2026.04.23 |
| SQL with 빅쿼리 - WITH문, WHERE문, 순위함수, 집계함수, 그룹함수 (0) | 2026.04.23 |



