🚀 Amazon 데이터셋 기반 추천 시스템 설계 프로젝트
📌 프로젝트 개요
이번 프로젝트는 Amazon 데이터셋을 기반으로 고객 맞춤형 추천 시스템을 설계하고 구현하는 작업입니다. Amazon은 전 세계적으로 가장 큰 전자상거래 플랫폼 중 하나로, 방대한 고객 리뷰와 제품 데이터를 보유하고 있습니다.
이번 프로젝트에서는 이러한 데이터를 SQL만을 사용하여 분석하고, 고객의 구매 경험을 향상시킬 수 있는 추천 시스템의 기초를 설계하는 것이 목표입니다.
🎯 학습 목표
데이터 이해 및 탐색
먼저 Amazon 데이터셋을 분석하여 고객과 제품 간의 상호작용 데이터를 이해합니다. 고객 리뷰, 평점, 제품 카테고리 등 다양한 데이터를 활용해 주요 인사이트를 도출합니다.
추천 시스템 설계 및 구현
SQL을 사용해 인기 제품 추천, 고객 선호도를 기반으로 한 추천, 유사 제품 추천 등 다양한 추천 셋을 제안할 겁니다. 여러분은 동일한 데이터를 다양한 각도에서 분석해보면서 새로운 서비스에 활용할 수 있는 가능성을 분석적으로 보여주시면 됩니다.
📌 주요 개념
| 필드명 | 설명 |
|---|---|
| product_id | 제품의 고유 식별자 |
| product_name | 제품의 이름 |
| category | 제품이 속한 카테고리 정보 |
| discounted_price | 할인된 가격 |
| actual_price | 정가 |
| discount_percentage | 할인율 |
| rating | 제품의 평균 평점 |
| rating_count | 제품에 대한 총 평점 수 |
| about_product | 제품에 대한 간단한 설명 |
| user_id | 리뷰를 작성한 사용자의 고유 식별자 (쉼표로 구분된 여러 사용자) |
| user_name | 리뷰를 작성한 사용자 이름 (쉼표로 구분된 여러 사용자) |
| review_id | 리뷰의 고유 식별자 (쉼표로 구분된 여러 리뷰) |
| review_title | 리뷰 제목 (쉼표로 구분된 여러 리뷰 제목) |
| review_content | 리뷰 내용 (쉼표로 구분된 여러 리뷰 내용) |
| img_link | 제품 이미지 URL |
| product_link | 제품 페이지 URL |
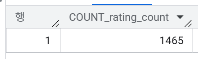
- 전체 데이터 몇 행 몇 컬럼? 1465행 / 16컬럼
- 데이터 타입
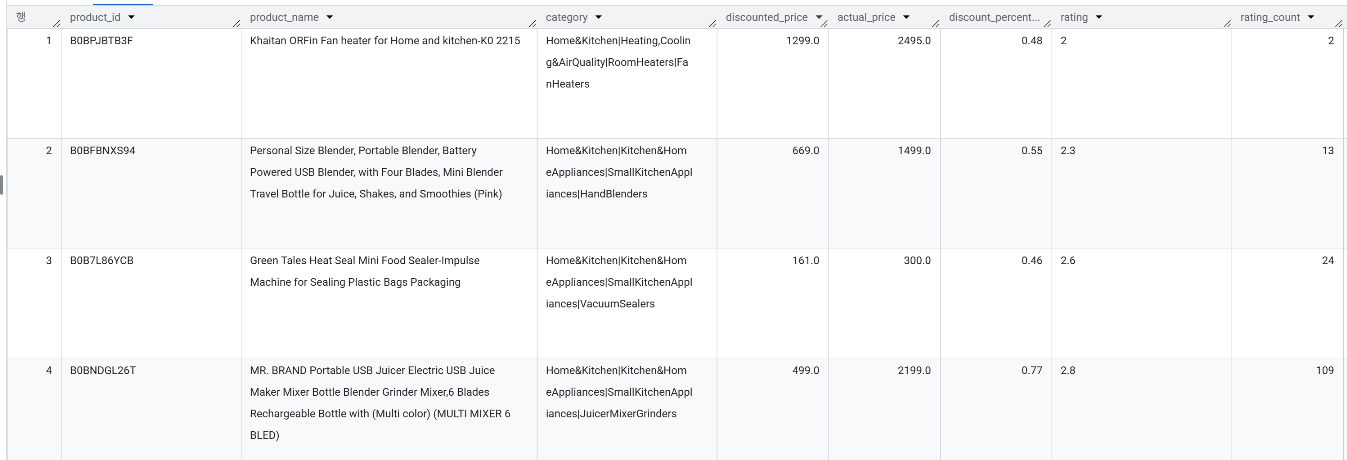
- 데이터 헤드
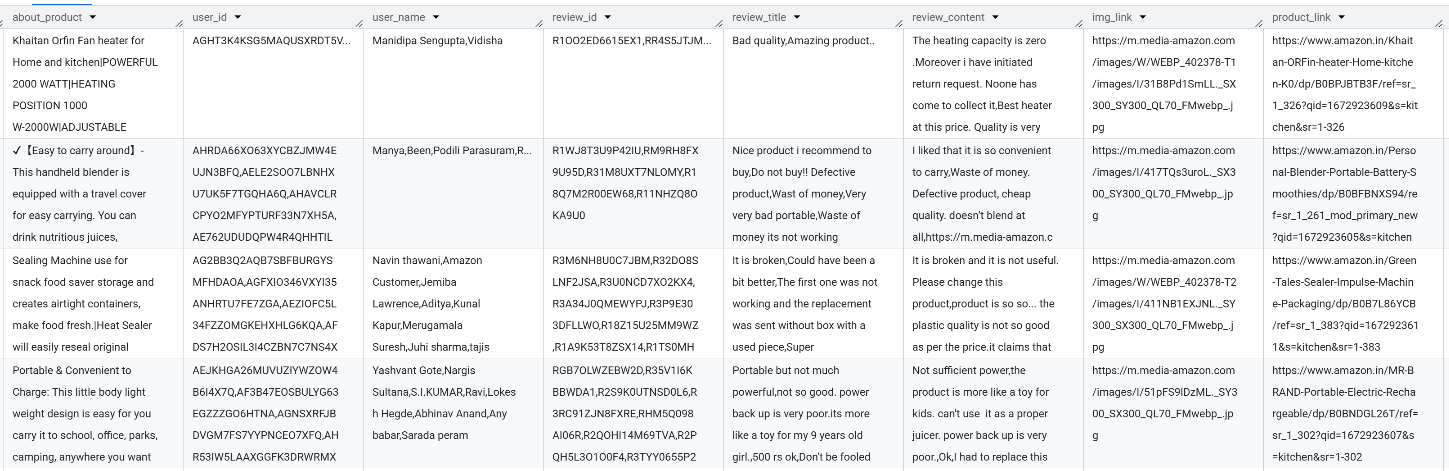

📌 데이터 전처리
불필요 컬럼 제거(16컬럼 → 14컬럼)
img_link,product_link: 두 컬럼은 분석에 불필요하다 판단되어 제거했습니다.
CREATE OR REPLACE TABLE `modulabs_project.amazon` AS
SELECT
product_id,
product_name,
category,
discounted_price,
actual_price,
discount_percentage,
rating,
rating_count,
about_product,
user_id,
user_name,
review_id,
review_title,
review_content
FROM `modulabs_project.amazon_raw` 결측치 처리

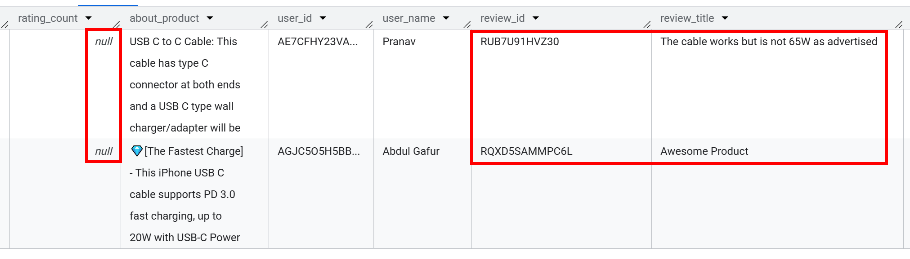
rating_count결측치 확인 → 결측값 2행 존재했으나, 실제 리뷰 데이터가 1개씩 있음 → 1로 채우기로 결정
UPDATE `modulabs_project.amazon`
SET rating_count = 1
WHERE rating_count IS NULL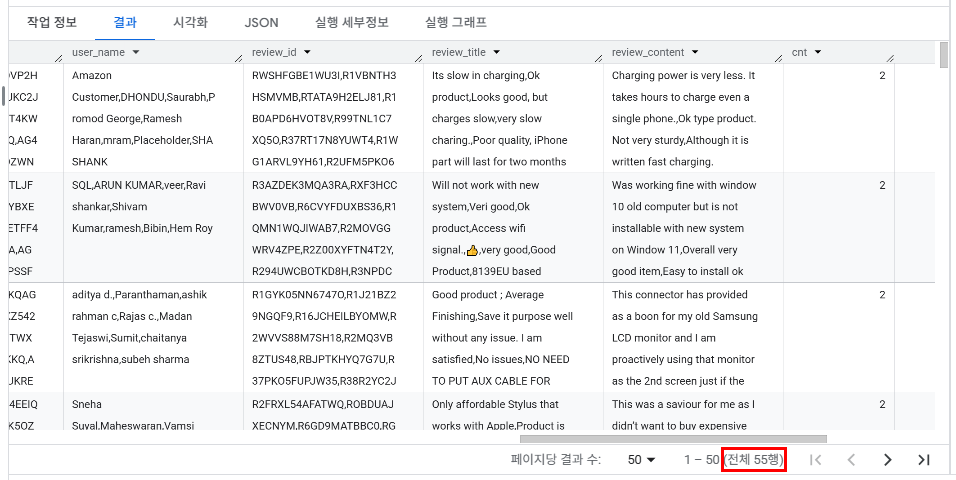
중복 데이터 확인
- 완전 동일 행 중복 여부 : 전체 55행(완전 동일 행이 각각 2~3개 존재함)
SELECT *, COUNT(*) as cnt
FROM `modulabs_project.amazon`
GROUP BY ALL
HAVING cnt > 1
- 완전 동일 행 제거 후 테이블 업데이트(1465행 → 1400행)
CREATE OR REPLACE TABLE `modulabs_project.amazon` AS
SELECT DISTINCT *
FROM `modulabs_project.amazon`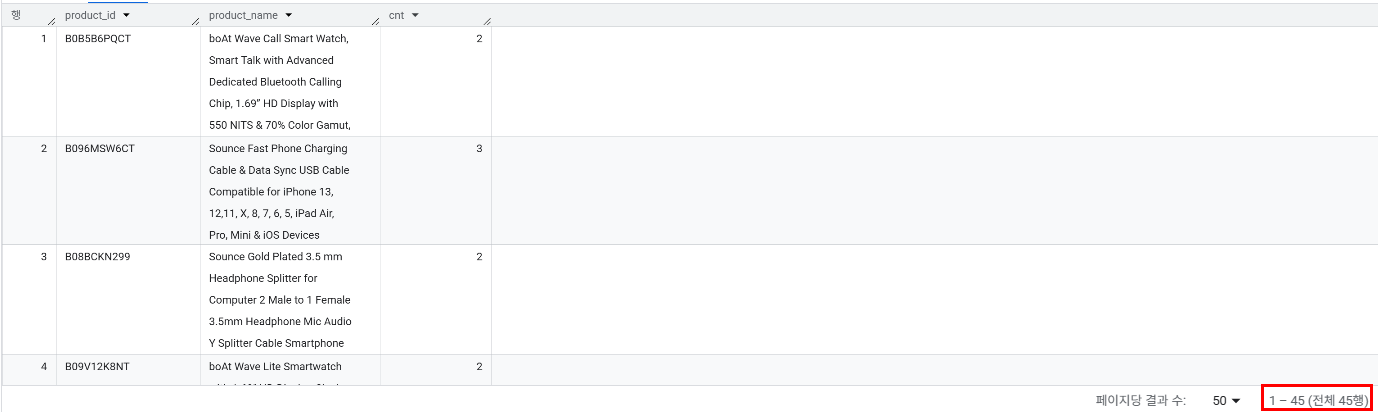
product_id,product_name중복 여부 : 같은 id, name을 가진 상품 총 45개(각각 2~3개 존재함)
SELECT product_id, product_name, COUNT(*) as cnt
FROM `modulabs_project.amazon`
GROUP BY product_id, product_name
HAVING cnt > 1
B0B5B6PQCT: 같은 상품인데 시기에 따라 할인율이 다르고 리뷰 개수가 다름 → 리뷰 개수가 더 많은 상품이 더 최신 데이터라고 가정하고 선택하여 업데이트
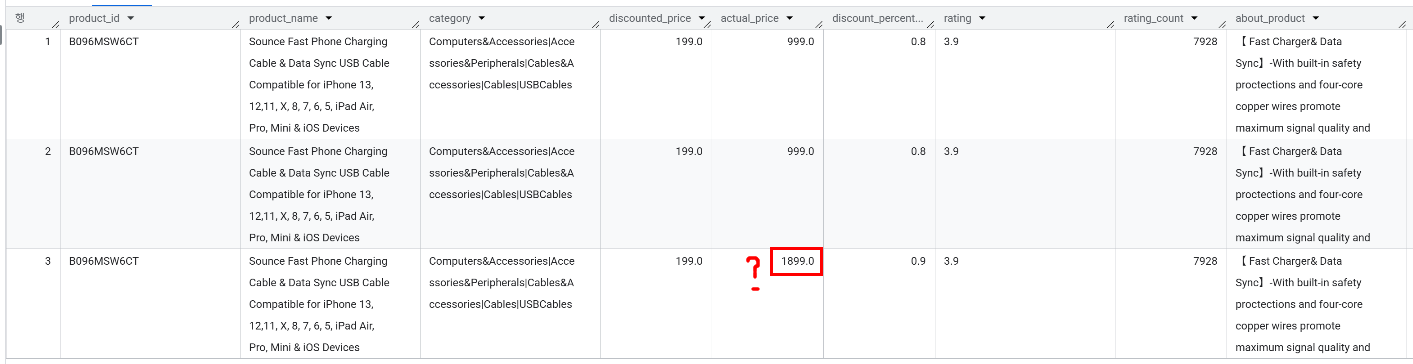
B096MSW6CT: 리뷰 개수가 같은데 원가가 다름 데이터 오류거나 시기가 다를 가능성이 있어보임

B08BCKN299: 눈으로 확인했을 때, 완전 동일해보임


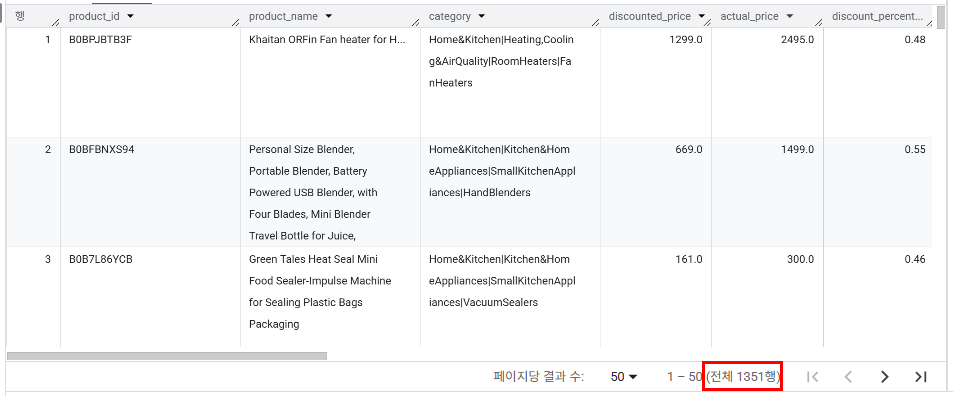
- 3가지 상품을 뽑아서 직접 중복 데이터 확인한 후 중복 데이터 정리 3가지 기준 정의
→ 같은 상품 중에서 리뷰 수가 더 많은 상품이 최신 데이터일 확률이 높기 때문에 선택
→ 리뷰 수가 같으면 할인율이 큰 상품으로 소비자 입장에서 더 싸게 살 수 있는 상품으로 선택
→ 할인율도 같다면 평점이 더 높은 상품으로 선택
- 중복 상품 데이터 제거 후 테이블 업데이트(1400행 → 1351행)
CREATE OR REPLACE TABLE `modulabs_project.amazon` AS
SELECT *
EXCEPT(rn)
FROM (
SELECT *,
ROW_NUMBER() OVER (
PARTITION BY product_id
ORDER BY rating_count DESC, discount_percentage DESC, rating DESC
) AS rn
FROM `modulabs_project.amazon`
)
WHERE rn = 1
rating:STRING타입으로 되어있음
→ | 들어가 있는 1행 삭제하고 FLOAT64 타입으로 수정 (1351행 → 1350행)
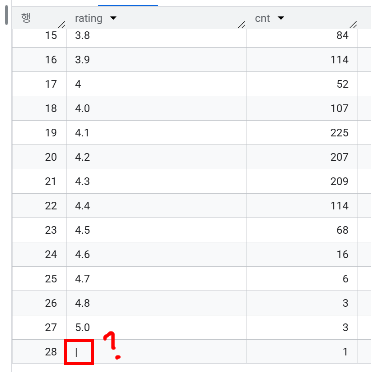
# 이렇게 변경해주면 해당 rating 컬럼 테이블에서 제일 마지막에 들어감
# FLOAT로 하면 에러남 FLOAT64로 변경해줘야함
CREATE OR REPLACE TABLE `modulabs_project.amazon` AS
SELECT
* EXCEPT(rating),
CAST(rating AS FLOAT64) AS rating
FROM `modulabs_project.amazon`# 원하는 위치에 넣으려면 전체 컬럼 순서에 맞춰서 넣어줘야함
CREATE OR REPLACE TABLE `modulabs_project.amazon` AS
SELECT
product_id,
product_name,
category,
discounted_price,
actual_price,
discount_percentage,
CAST(rating AS FLOAT64) AS rating,
rating_count,
about_product,
user_id,
user_name,
review_id,
review_title,
review_content
FROM `modulabs_project.amazon`
📌 데이터 EDA
- 고유한
product_id가 몇 개인가? 1350개 - 고유한
product_name은 몇 개인가? 1336개 product_id컬럼을 제외product_name뿐 아니라 전체 컬럼이 완전 동일한 제품인지 확인
→ product_id 는 다르고 나머지 컬럼 완전히 동일 3개짜리 1개, 2개짜리 5개 총 6개 상품 그룹에서 중복 발생 → id를 제외한 모든 컬럼이 동일한 상품 중복 제거(1350행 → 1343행)
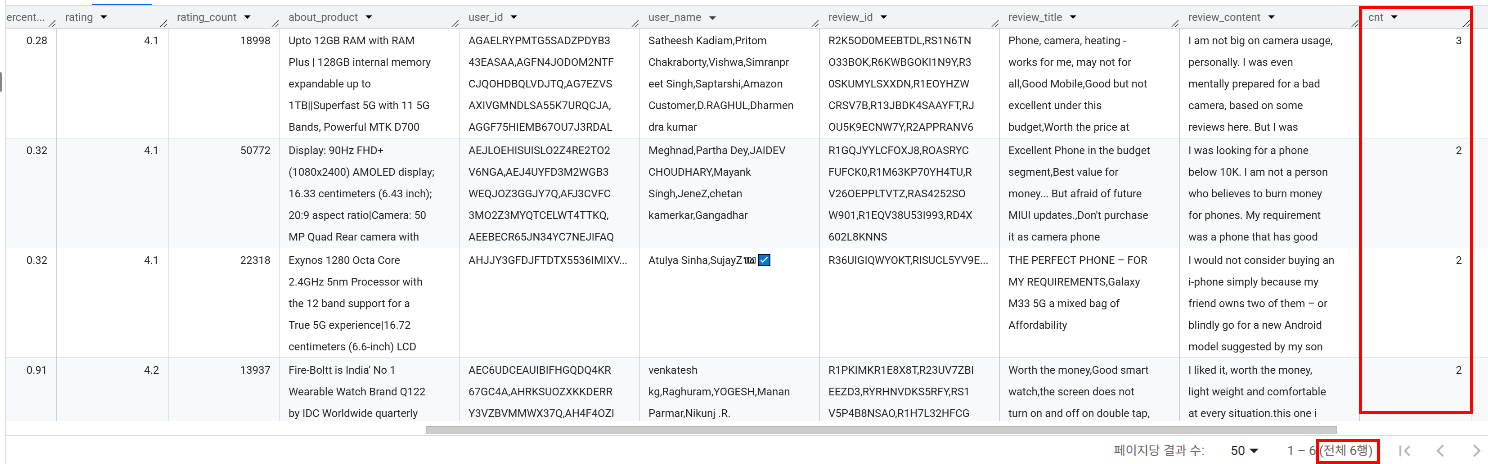
- 고유한
product_id가 몇 개인가? 1343개 - 고유한
product_name은 몇 개인가? 1336개
Firestick Remote: 2개 → 다른 상품으로 확인 그대로 유지

Fire-Boltt India's No 1 Smartwatch Brand Talk 2 Bluetooth Calling Smartwatch with Dual Button, Hands On Voice Assistance, 60 Sports Modes, in Built Mic & Speaker with IP68 Rating: 2개 → 같은 상품으로 판단하여 리뷰 수 적은 상품 1개 제거

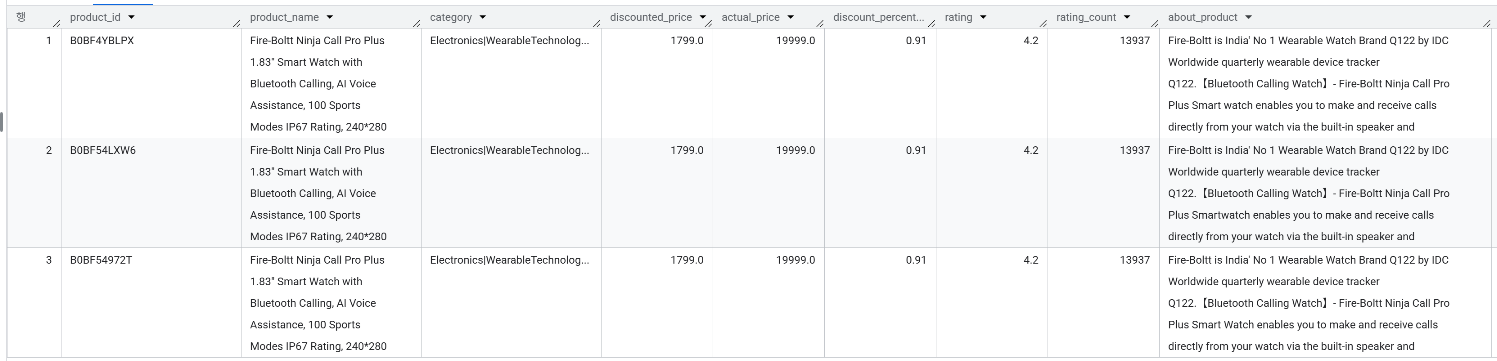
Fire-Boltt Ninja Call Pro Plus 1.83" Smart Watch with Bluetooth Calling, AI Voice Assistance, 100 Sports Modes IP67 Rating, 240*280 Pixel High Resolution: 3개 → 같은 상품으로 판단하여 2개 제거
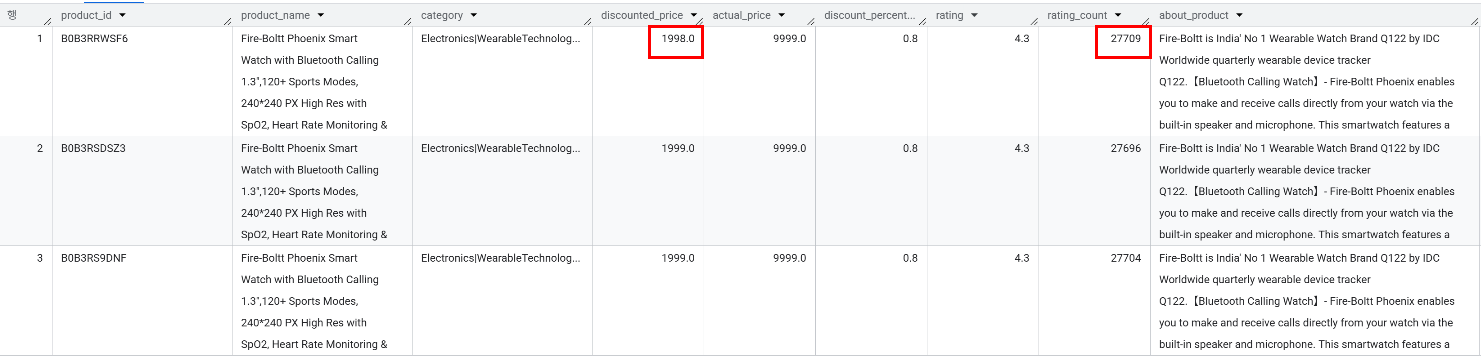
Fire-Boltt Phoenix Smart Watch with Bluetooth Calling 1.3",120+ Sports Modes, 240*240 PX High Res with SpO2, Heart Rate Monitoring & IP67 Rating: 3개 → 같은 상품으로 판단하여 리뷰 수 적은 상품 2개 제거
Fire-Boltt Visionary 1.78" AMOLED Bluetooth Calling Smartwatch with 368*448 Pixel Resolution 100+ Sports Mode, TWS Connection, Voice Assistance, SPO2 & Heart Rate Monitoring: 2개 → 같은 상품으로 판단하여 리뷰 수 적은 상품 1개 제거

- 중복 상품 6행 제거 (1343행 → 1337행) :
product_name기준 중복 상품은Firestick Remote2개만 있는 것으로 확인

- 고평점 상품이 많은가? 평점 별 개수는? 1점대는 없는 것으로 확인되었고 대부분 3~4점대에 몰려있음
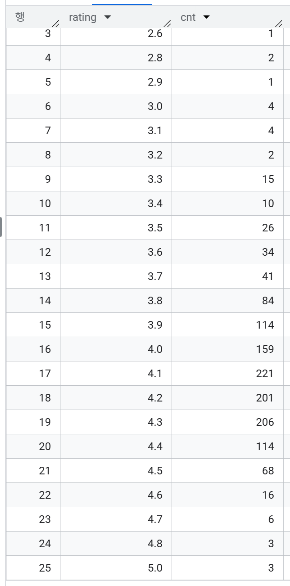
- 평점 별 평균 리뷰 수는? 5점짜리 상품은 3개에 리뷰 수도 굉장히 적음
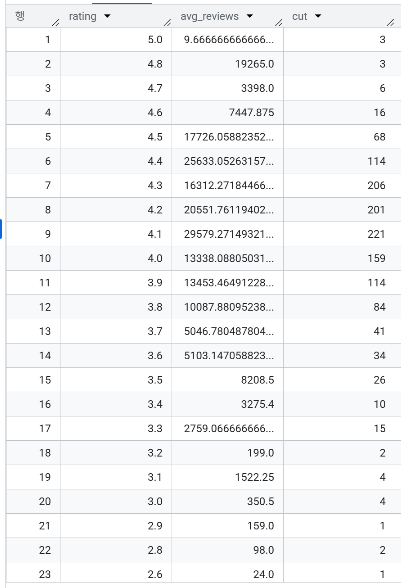
- 카테고리를 '|’ 기준으로 cat_1, cat_2, cat_3까지 나눴을 때, cat_1의 분포는? 총 9종류
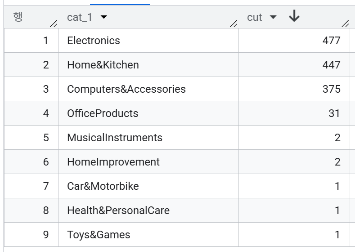
- cat_2 에는 어떤 상품들이 있는가? 총 29종류
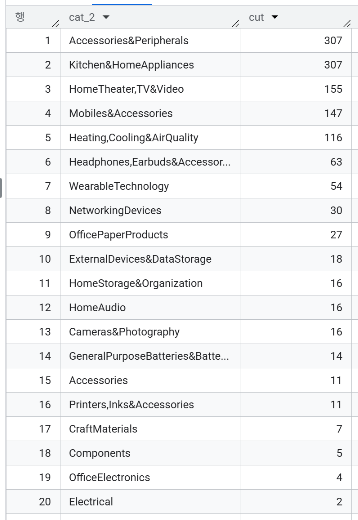
- cat_1(Electronics) 하위 카테고리 분포
SELECT cat_2, COUNT(*) AS cut
FROM `modulabs_project.amazon_cat_split`
WHERE cat_1 = 'Electronics'
GROUP BY cat_2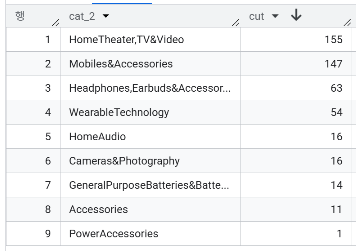
- cat_1(Home&Kitchen) 하위 카테고리 분포
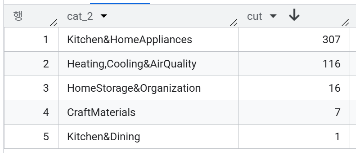
- cat_1(Computers&Accessories) 하위 카테고리 분포
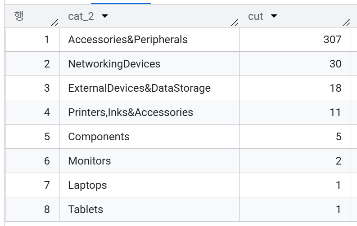
- cat_3 에는 어떤 상품들이 있는가? 총 72종류
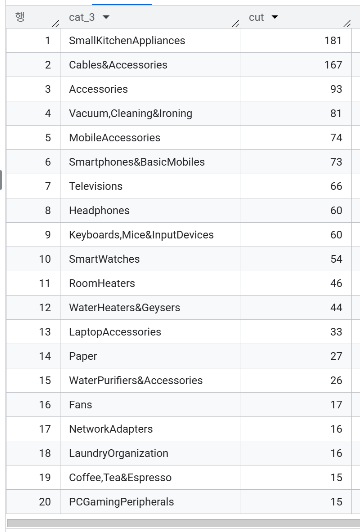
- cat_3 기준으로 카운트 세고 cat_1, cat_2 함께 확인
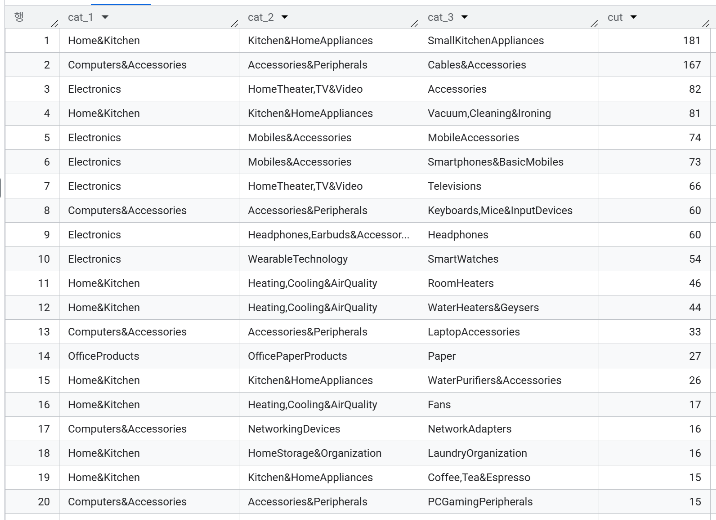
- 같은 소분류(
cat_3) 안에서MIN,MAX,AVG은 얼마인지? 전체적으로 카테고리별 가장 싼 상품과 가장 비싼 상품의 가격 차이가 많이 남
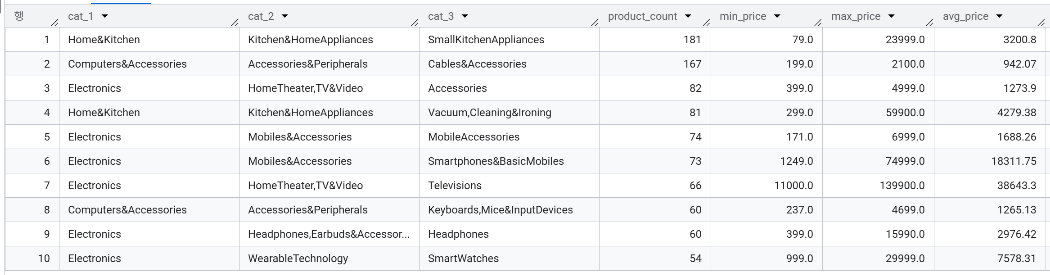
추천 시스템 1️⃣
1. 추천 시스템 이름
→ “놓치면 후회하는 초특가 득템 상품 추천” (할인율이 높은 가성비 & 고평점 결합 추천)
2. 추천 시스템의 테마
→ 단순히 할인율만 높으면 안 팔려서 할인 하는 제품일 수 있다고 생각하여, 리뷰 수와 평점으로 필터링하여 ‘진짜 좋은데 싸게 파는 제품’을 추천
→ 일정 수준 이상의 검증된 퀄리티를 갖춘 상품 중 할인율이 가장 높은 상품 추천
3. 구현 로직
→ 평점 4.0 이상, 리뷰 수 100개 이상, 50% 이상의 할인율 조건을 걸고 할인율이 높은 순으로 정렬하고 평점도 높은 순으로 정렬했습니다.
SELECT
product_id,
product_name,
discounted_price,
actual_price,
discount_percentage,
rating,
rating_count,
cat_1,
cat_2,
cat_3
FROM `modulabs_project.amazon_cat_split`
WHERE rating >= 4.0
AND rating_count >= 100
AND discount_percentage >= 0.5
ORDER BY discount_percentage DESC, rating DESC
LIMIT 5
4. 결과
→ 1위로 추천된 USB C타입 어댑터의 경우, 94%의 높은 할인율을 보이면서도 4,400개가 넘는 리뷰와 4.3점의 우수한 평점을 보유하고 있습니다. 2위인 스마트워치(Fire-Boltt) 역시 13,000개가 넘는 압도적인 리뷰 수와 4.2점의 평점을 기록한 인기 상품임에도 무려 91%의 할인이 적용되었습니다. 결과적으로 “놓치면 후회하는 초특가 득템”이라는 시스템의 기획 의도에 맞게, 품질이 검증된 파격 할인 상품들이 성공적으로 필터링 된 것을 확인할 수 있었습니다.
→ 비즈니스 기대 효과 : 단순히 안 팔리는 악성 재고를 할인 기준으로만 묶어서 보여주는 것이 아니라, “많은 사람들이 이미 만족한 인기 상품을 현재 엄청 싸게 살 수 있다”는 점을 어필함으로써 고객의 구매 전환율을 올릴 수 있습니다.
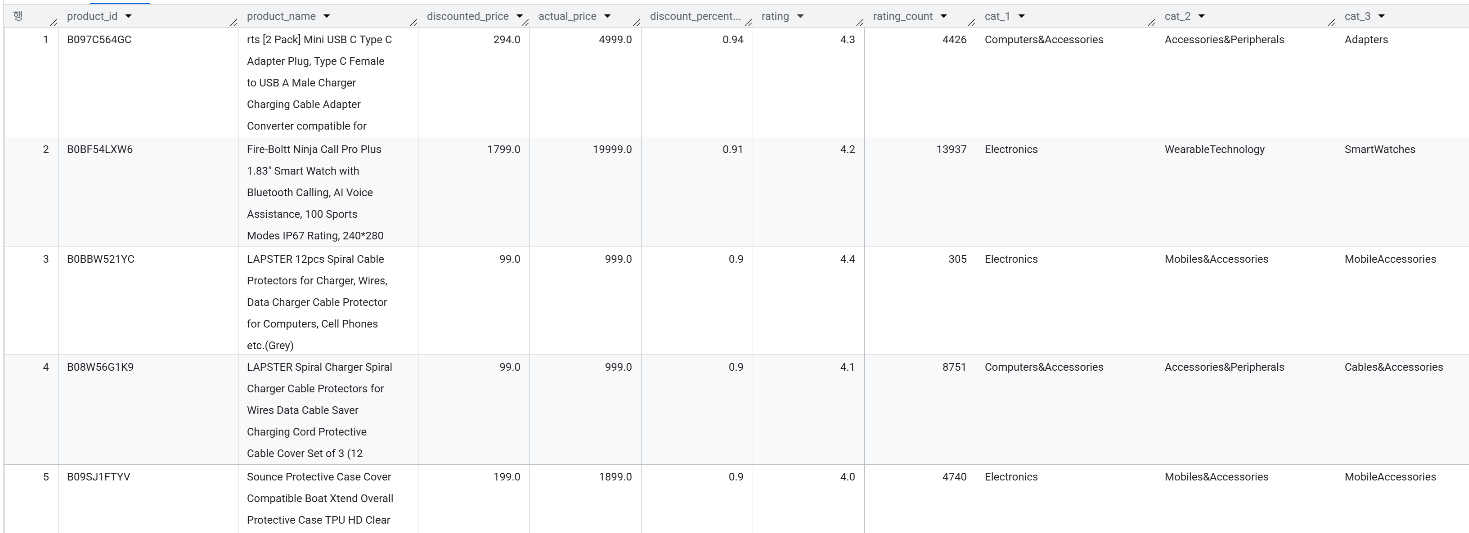
추천 시스템 2️⃣
1. 추천 시스템 이름
→ “카테고리별 베스트 상품 추천” (세분화된 카테고리 랭킹 추천)
2. 추천 시스템의 테마
→ cat_3(소분류)별 상위 1~3위(Top 3) 상품을 뽑아내서 추천
3. 구현 로직
→ cat_3(소분류)별 상품 수가 가장 많은 핵심 카테고리 5개에서 평점과 리뷰 수를 기준으로 순위 부여하고 최소 리뷰 수 50개 이상 기준을 추가했습니다.
WITH RankedProducts AS (
SELECT
cat_1,
cat_2,
cat_3,
product_id,
product_name,
rating,
rating_count,
ROW_NUMBER() OVER(PARTITION BY cat_3 ORDER BY rating DESC, rating_count DESC) as rnk
FROM `modulabs_project.amazon_cat_split`
WHERE
cat_3 IN (
'SmallKitchenAppliances',
'Cables&Accessories',
'Accessories',
'Vacuum,Cleaning&Ironing',
'MobileAccessories'
)
AND rating_count >= 50
)
SELECT
cat_1,
cat_2,
cat_3,
rnk AS category_rank,
product_id,
product_name,
rating,
rating_count
FROM RankedProducts
WHERE rnk <= 3
ORDER BY cat_1, cat_2, cat_3, rnk
4. 결과
→ cat_1(대분류)부터 cat_3(소분류)까지 함께 나열하여, 고객이 현재 어떤 카테고리의 랭킹을 보고 있는지 직관적으로 파악할 수 있도록 가독성을 높이고, Cables&Accessories 카테고리에서는 무려 10만 개가 넘는 압도적인 리뷰 수를 가진 'AmazonBasics USB 케이블' 시리즈가 1~3위를 휩쓸며 해당 분야에서의 베스트 상품임을 입증하고, Accessories 소분류라는 이름이라도 상위 카테고리에 따라 카메라용 필름과 홈시어터용 HDMI 케이블로 명확히 나뉘어 각각의 베스트셀러가 정확히 추천되는 것을 확인할 수 있었습니다.
→ 비즈니스 기대 효과 : 고객이 특정 목적을 가지고 카테고리에 진입했을 때, 가장 대중적으로 검증된 상품을 1위부터 3위까지 추천해줌으로써 탐색 피로도를 줄이고 빠른 구매 결정을 유도할 수 있습니다.
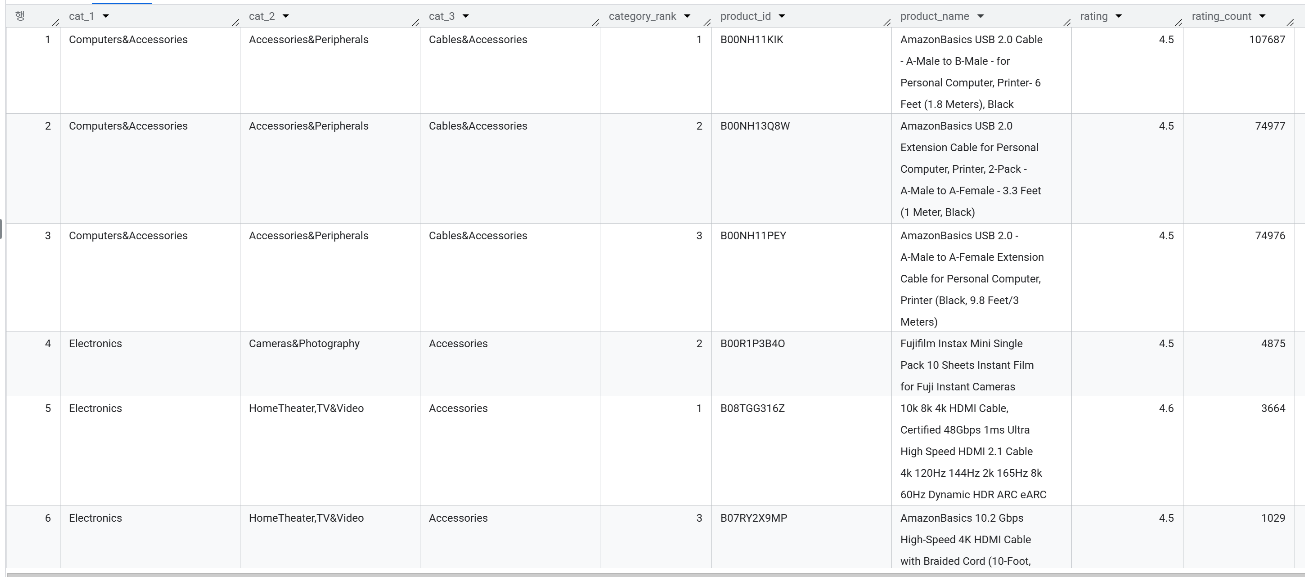
추천 시스템 3️⃣
1. 추천 시스템 이름
→ “이 상품을 본 고객들이 함께 찾은 상품 추천” (유저 기반 연관 추천)
2. 추천 시스템의 테마
→ A상품을 리뷰한 유저가 B상품도 리뷰했다는 동시 구매(리뷰) 패턴을 찾아 연관 상품 추천
3. 구현 로직
→ user_id 컬럼을 활용하여 , 기준으로 유저를 분리하여 동시 구매한 상품을 찾습니다.
WITH UnnestedUsers AS (
SELECT
product_id,
product_name,
cat_3,
TRIM(user) AS user_id
FROM `modulabs_project.amazon_cat_split`,
UNNEST(SPLIT(user_id, ',')) AS user
WHERE user != ''
)
SELECT
t1.product_id AS target_product_id,
t1.product_name AS target_product_name,
t1.cat_3 AS target_category,
t2.product_id AS recommended_product_id,
t2.product_name AS recommended_product_name,
COUNT(DISTINCT t1.user_id) AS co_purchase_count -- 동시 구매/리뷰 유저 수
FROM UnnestedUsers t1
JOIN UnnestedUsers t2
ON t1.user_id = t2.user_id
AND t1.product_id != t2.product_id -- 자기 자신은 제외
GROUP BY t1.product_id, t1.product_name, t1.cat_3, t2.product_id, t2.product_name
ORDER BY co_purchase_count DESC
LIMIT 10
4. 결과
→ 동일한 고객(user_id)이 함께 구매하거나 리뷰를 남긴 이력이 가장 많은 상품 함께을 추출했는데, target_product_id와 recommended_product_id가 다르지만 상품명은 거의 동일한 '색상/옵션/버전 차이' 상품들이 상위권을 차지했습니다. 아마존 특성상 색상이나 세부 스펙 모델이 다른 같은 상품들이 서로 다른 상품 ID를 가지고 있어 나타난 결과이며, 고객들이 스마트워치나 모바일 액세서리를 구매할 때에 동일 라인업의 다른 색상이나 세부 스펙 모델을 동시에 구매하거나 비교하는 데이터 특성을 확인할 수 있었습니다.
→ 비즈니스 기대 효과 : 고객이 특정 상품을 보고 있을 때, 다른 고객들이 함께 비교하거나 구매한 다른 옵션을 제시하여 고객이 원하는 정확한 옵션(색상, 사이즈 등)을 찾지 못해 이탈하는 것을 방지하고, 또는 “이 색상도 예쁜데 같이 살까?”하는 추가 구매를 유도할 수 있습니다.
추천 시스템 4️⃣
1. 추천 시스템 이름
→ “리뷰가 증명하는 진짜 찐템 상품 추천” (신뢰도 점수 기반 추천)
2. 추천 시스템의 테마
→ 점 5.0인데 리뷰가 1개인 상품과, 별점 4.7인데 리뷰가 10,000개인 상품 중 어느 것이 더 신뢰할 수 있는가 당연 후자의 상품을 신뢰할 것 입니다. 이를 수학적으로 보정하여 진정한 인기 상품을 추천
→ 소수의 리뷰로 인한 높은 평점은 제거하고, 리뷰 수와 평점을 종합적으로 고려한 ‘신뢰도 가중치 점수(Weighted Score)' 기반 추천
3. 구현 로직
→ 베이지안 평균(Bayesian Average) 또는 가중 평점(Weighted Rating)은 데이터셋이 작거나 평점이 불균형할 때, 단순 평균의 신뢰성 문제를 보완하기 위해 사용하는 통계적 평균 방식입니다. 사전 정보(전체 평균)를 바탕으로 데이터가 적은 항목의 평점을 보정하여 신뢰도를 높이는 것이 핵심입니다.
→ 리뷰 수가 적은 상품이 상위권에 랭크되는 '단순 평균의 오류'를 방지하기 위해, 실무 추천 시스템에서 활용되는 베이지안 평균(Bayesian Average) 기반의 가중 평점을 활용하여 파생 변수를 만들었습니다.
→ (rating * rating_count) / (rating_count + 최소임계값 = 100) 연산을 통해 trust_score라는 새로운 컬럼을 만들었습니다. 이 공식을 활용했을 때, 리뷰가 2개인 5점짜리 상품은 0.09점이 나오고 리뷰가 5000개인 4.8점짜리 상품은 4.7점으로 평점이 거의 그대로 유지되며 신뢰도 점수가 높기 때문에 실제로 리뷰가 증명하는 찐템 상품이라고 생각할 수 있습니다.
WITH TrustScoreCalc AS (
SELECT
cat_3,
product_id,
product_name,
rating,
rating_count,
-- 신뢰도 점수(가중 평점) 공식
-- (실제 평점 * 실제 리뷰수) / (실제 리뷰수 + 100)
(rating * rating_count) / (rating_count + 100) AS trust_score
FROM `modulabs_project.amazon_cat_split`
WHERE rating_count IS NOT NULL
)
SELECT
cat_3,
product_id,
product_name,
rating,
rating_count,
ROUND(trust_score, 2) AS trust_score
FROM TrustScoreCalc
ORDER BY trust_score DESC
LIMIT 10
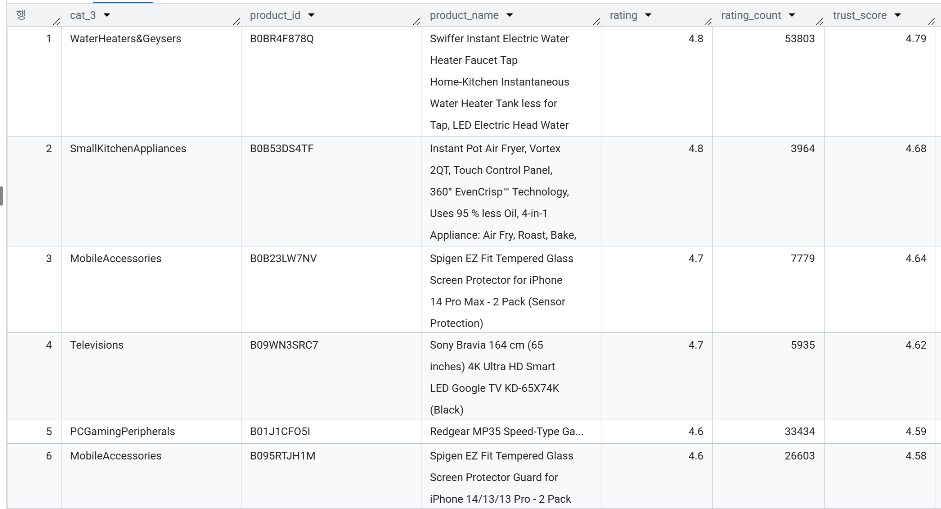
4. 결과
→ 1위(Water Heater)와 2위(Instant Pot) 상품은 원래 평점(rating)이 4.8점으로 동일합니다. 하지만 리뷰 수가 약 53,000개인 1위 상품은 신뢰도 점수(trust_score)가 4.79점으로 원래 평점을 거의 유지했고, 리뷰 수가 약 3,900개인 2위 상품은 4.68점으로 약간의 페널티가 적용된 것을 확인할 수 있었습니다.
→ 비즈니스 기대 효과 : 고객에게 객관적으로 가장 많이 검증된, 실패 확률이 적은 고품질 상품을 우선적으로 추천함으로써 아마존에 대한 고객의 신뢰도를 높이고 반품률을 낮출 수 있습니다.
추천 시스템 5️⃣
1. 추천 시스템 이름
→ “나의 지갑 사정에 맞는 맞춤 제안 (프리미엄 vs 가성비) 추천”
2. 추천 시스템의 테마
→ 동일한 종류의 상품을 찾더라도 유저마다 예산이 다르기 때문에 동일한 소분류(cat_3) 내에서 가장 비싼 그룹의 프리미엄 상품 1개와 가장 저렴한 가성비 그룹의 예산 절약형 상품 1개를 함께 추천
3. 구현 로직
→ cat_3 내 상품들의 가격(actual_price)을 기준으로 고가, 중가, 저가 3가지 등급으로 나눴습니다.
→ 너무 적은 상품 수를 가진 카테고리는 제대로 나눠지지 않을 가능성이 있어 cat_3 내 상품 수가 가장 많은 Top 3 카테고리로 확인했습니다.
WITH PriceCategories AS (
SELECT
cat_1,
cat_2,
cat_3,
product_id,
product_name,
actual_price,
rating,
rating_count,
NTILE(3) OVER(PARTITION BY cat_3 ORDER BY actual_price DESC) AS price_tier
FROM `modulabs_project.amazon_cat_split`
WHERE rating_count >= 50
-- 상품 수가 충분히 확보된 핵심 카테고리 3개만 필터링
AND cat_3 IN ('SmallKitchenAppliances', 'Cables&Accessories', 'Accessories')
),
TopPerTier AS (
SELECT
cat_1,
cat_2,
cat_3,
price_tier,
product_id,
product_name,
actual_price,
rating,
rating_count,
ROW_NUMBER() OVER(PARTITION BY cat_3, price_tier ORDER BY rating DESC, rating_count DESC) as rnk
FROM PriceCategories
)
SELECT
cat_1,
cat_2,
cat_3,
CASE
WHEN price_tier = 1 THEN '👑 프리미엄 (하이엔드)'
WHEN price_tier = 3 THEN '💸 가성비 (실속형)'
END AS recommendation_type,
product_id,
product_name,
actual_price,
rating,
rating_count
FROM TopPerTier
WHERE rnk = 1
AND price_tier IN (1, 3)
ORDER BY cat_1, cat_2, cat_3, price_tier
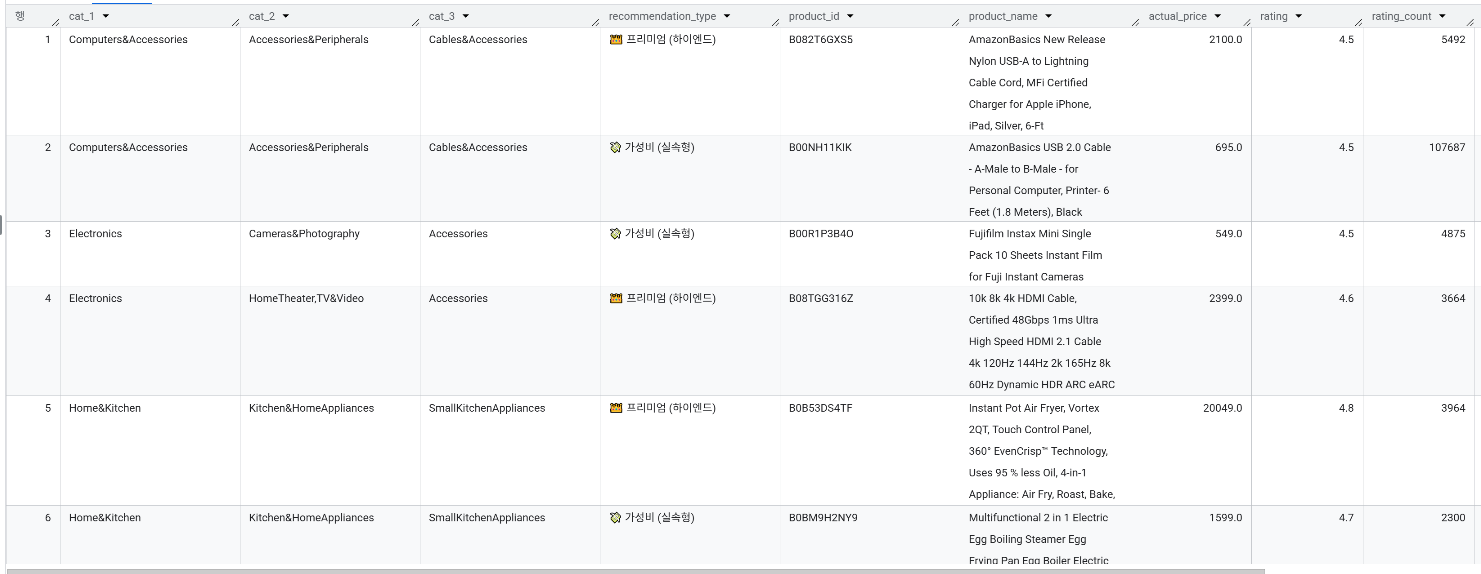
4. 결과
→ 소형 주방가전(SmallKitchenAppliances) 카테고리를 보면, 프리미엄 라인으로는 고가 하이엔드 기기인 인스턴트 팟(Instant Pot)이, 가성비 라인으로는 실속형 계란 찜기(Egg Boiler)가 나란히 추천되었습니다. 같은 카테고리 내에서 예산 차이를 명확하게 확인 할 수 있었습니다.
→ 비즈니스 기대 효과 : 고객이 특정 카테고리에 진입했을 때, 가장 비싸고 좋은 모델 vs 가장 가성비 좋은 모델을 동시에 추천받음으로써 가격 장벽으로 인한 고객 이탈을 막고 구매 전환율을 높일 수 있습니다.
'IT' 카테고리의 다른 글
| SQL with 빅쿼리 - 유저 행동 변화 분석 및 오프라인 매장 분석 (0) | 2026.04.25 |
|---|---|
| SQL with 빅쿼리 - 마케팅 캠페인 성과분석 (0) | 2026.04.24 |
| SQL with 빅쿼리 - 이커머스 전환율 분석 및 상품 추천 전략 수립 (1) | 2026.04.23 |
| SQL with 빅쿼리 - PV, UV, ARPU, ARPPU, AARRR, 리텐션 분석 (1) | 2026.04.23 |
| SQL with 빅쿼리 - WITH문, WHERE문, 순위함수, 집계함수, 그룹함수 (0) | 2026.04.23 |



